Lesson type
Difficulty level

This lecture presents the Medical Informatics Platform's data federation in epilepsy.
Difficulty level: Intermediate
Duration: 27:09
Speaker: : Philippe Ryvlin

This lecture aims to help researchers, students, and health care professionals understand the place for neuroinformatics in the patient journey using the exemplar of an epilepsy patient.
Difficulty level: Intermediate
Duration: 1:32:53
Speaker: : Randy Gollub & Prantik Kundu

In this lesson, the simulation of a virtual epileptic patient is presented as an example of advanced brain simulation as a translational approach to deliver improved clinical results. You will learn about the fundamentals of epilepsy, as well as the concepts underlying epilepsy simulation. By using an iPython notebook, the detailed process of this approach is explained step by step. In the end, you are able to perform simple epilepsy simulations your own.
Difficulty level: Beginner
Duration: 1:28:53
Speaker: : Julie Courtiol

Explore how to setup an epileptic seizure simulation with the TVB graphical user interface. This lesson will show you how to program the epileptor model in the brain network to simulate a epileptic seizure originating in the hippocampus. It will also show how to upload and view mouse connectivity data, as well as give a short introduction to the python script interface of TVB.
Difficulty level: Intermediate
Duration: 58:06
Speaker: : Paul Triebkorn

Course:
In this lesson you will learn how to simulate seizure events and epilepsy in The Virtual Brain. We will look at the paper On the Nature of Seizure Dynamics, which describes a new local model called the Epileptor, and apply this same model in The Virtual Brain. This is part 1 of 2 in a series explaining how to use the Epileptor. In this part, we focus on setting up the parameters.
Difficulty level: Beginner
Duration: 4:44
Speaker: : Paul Triebkorn

This talk introduces data sharing initiatives in Epilepsy, particularly across Europe.
Difficulty level: Intermediate
Duration: 13:56
Speaker: : J. Helen Cross

The epilepsy SP actively promotes and supports epilepsy-related issues as well as educational and scientific activities within the framework of EAN. Our partners ILAE/ILAE Europe, EpiCare, EPNS and AOAN are actively involved. One of the major tasks is promoting submissions of session proposals for EAN congress balancing new scientific approaches and educational need for teaching courses. Outside of congress activities, contributions to e-learning facilities on the EAN website such as registrars reading list, scales and scores and breaking news are regularly presented or updated. Particular since the COVID pandemic, publications on COVID and any issues of epilepsy or seizures are regularly screened and summarized in neurology updates. In partnership with the ILAE/ILAE Europe, several guidelines are under preparation.
Difficulty level: Intermediate
Duration: 14:56
Speaker: : Tim J. von Oertzen

Course:
This session will include presentations of infrastructure that embrace the FAIR principles developed by members of the INCF Community. This lecture provides an overview and demo of the Canadian Open Neuroscience Platform (CONP).
Difficulty level: Beginner
Duration: 14:02
Speaker: : Tristan Glatard & Samir Das

Course:
This lesson is a general overview of overarching concepts in neuroinformatics research, with a particular focus on clinical approaches to defining, measuring, studying, diagnosing, and treating various brain disorders. Also described are the complex, multi-level nature of brain disorders and the data associated with them, from genes and individual cells up to cortical microcircuits and whole-brain network dynamics. Given the heterogeneity of brain disorders and their underlying mechanisms, this lesson lays out a case for multiscale neuroscience data integration.
Difficulty level: Intermediate
Duration: 1:09:33
Speaker: : Sean Hill

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman

This is a continuation of the talk on the cellular mechanisms of neuronal communication, this time at the level of brain microcircuits and associated global signals like those measureable by electroencephalography (EEG). This lecture also discusses EEG biomarkers in mental health disorders, and how those cortical signatures may be simulated digitally.
Difficulty level: Intermediate
Duration: 1:11:04
Speaker: : Etay Hay

This is the second of three lectures around current challenges and opportunities facing neuroinformatic infrastructure for handling sensitive data.
Difficulty level: Beginner
Duration: 48:26
Speaker: : Michael Schirner

In this lesson you will learn about current efforts towards integrating multimodal human brain data using the open source SCORE HED library schema.
Difficulty level: Beginner
Duration: 23:29
Speaker: : Dora Hermes

The lesson introduces the Brain Imaging Data Structure (BIDS), the community standard for organizing, curating, and sharing neuroimaging and associated data. The session focuses on understanding the BIDS framework, learning its data structure and validation processes.
Difficulty level: Intermediate
Duration: 38:52
Speaker: : Cyril Pernet

This session moves from BIDS basics into analysis workflows, focusing on how to turn raw, BIDS-organized data into derivatives using BIDS Apps and containers for reproducible processing. It compares end-to-end pipelines across fMRI and PET (and notes EEG/MEG), explains typical preprocessing choices, and shows how standardized inputs plus containerized tools (Docker/AppTainer) yield consistent, auditable outputs.
Difficulty level: Intermediate
Duration: 56:03
Speaker: : Martin Nørgaard

The session explains GDPR rules around data sharing for research in Europe, the distinction between law and ethics, and introduces practical solutions for securely sharing sensitive datasets. Researchers have more flexibility than commonly assumed: scientific research is considered a public interest task, so explicit consent for data sharing isn’t legally required, though transparency and informing participants remain ethically important. The talk also introduces publicneuro.eu, a controlled-access platform that enables sharing neuroimaging datasets with open metadata, DOIs, and customizable access restrictions while ensuring GDPR compliance.
Difficulty level: Intermediate
Duration: 31:12
Speaker: : Cyril Pernet
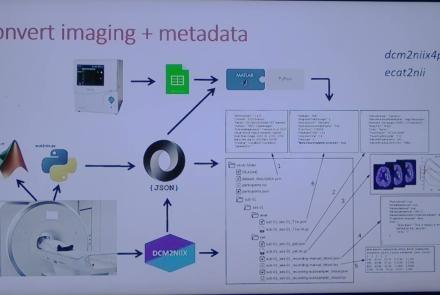
This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 9:23
Speaker: : Cyril Pernet

This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 41:04
Speaker: : Martin Nørgaard
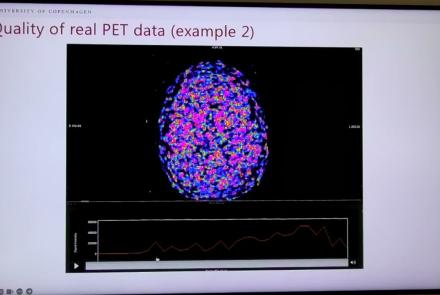
This session dives into practical PET tooling on BIDS data—showing how to run motion correction, register PET↔MRI, extract time–activity curves, and generate standardized PET-BIDS derivatives with clear QC reports. It introduces modular BIDS Apps (head-motion correction, TAC extraction), a full pipeline (PETPrep), and a PET/MRI defacer, with guidance on parameters, outputs, provenance, and why Dockerized containers are the reliable way to run them at scale.
Difficulty level: Intermediate
Duration: 1:05:38
Speaker: : Martin Nørgaard

This session introduces two PET quantification tools—bloodstream for processing arterial blood data and kinfitr for kinetic modeling and quantification—built to work with BIDS/BIDS-derivatives and containers. Bloodstream fuses autosampler and manual measurements (whole blood, plasma, parent fraction) using interpolation or fitted models (incl. hierarchical GAMs) to produce a clean arterial input function (AIF) and whole-blood curves with rich QC reports ready. TAC data (e.g., from PETPrep) and blood (e.g., from bloodstream) can be ingested using kinfitr to run reproducible, GUI-driven analyses: define combined ROIs, calculate weighting factors, estimate blood–tissue delay, choose and chain models (e.g., 2TCM → 1TCM with parameter inheritance), and export parameters/diagnostics. Both are available as Docker apps; workflows emphasize configuration files, reports, and standard outputs to support transparency and reuse.
Difficulty level: Intermediate
Duration: 1:20:56
Speaker: : Granville Matheson