Lesson type
Difficulty level

This lightning talk describes an automated pipline for positron emission tomography (PET) data.
Difficulty level: Intermediate
Duration: 7:27
Speaker: : Soodeh Moallemian
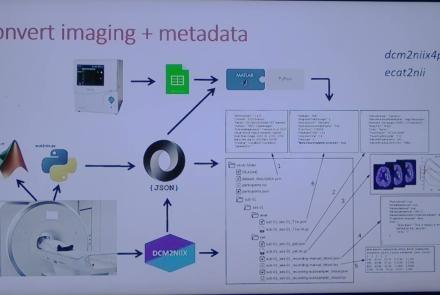
This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 9:23
Speaker: : Cyril Pernet

This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 41:04
Speaker: : Martin Nørgaard
This session dives into practical PET tooling on BIDS data—showing how to run motion correction, register PET↔MRI, extract time–activity curves, and generate standardized PET-BIDS derivatives with clear QC reports. It introduces modular BIDS Apps (head-motion correction, TAC extraction), a full pipeline (PETPrep), and a PET/MRI defacer, with guidance on parameters, outputs, provenance, and why Dockerized containers are the reliable way to run them at scale.
Difficulty level: Intermediate
Duration: 1:05:38
Speaker: : Martin Nørgaard

This session introduces two PET quantification tools—bloodstream for processing arterial blood data and kinfitr for kinetic modeling and quantification—built to work with BIDS/BIDS-derivatives and containers. Bloodstream fuses autosampler and manual measurements (whole blood, plasma, parent fraction) using interpolation or fitted models (incl. hierarchical GAMs) to produce a clean arterial input function (AIF) and whole-blood curves with rich QC reports ready. TAC data (e.g., from PETPrep) and blood (e.g., from bloodstream) can be ingested using kinfitr to run reproducible, GUI-driven analyses: define combined ROIs, calculate weighting factors, estimate blood–tissue delay, choose and chain models (e.g., 2TCM → 1TCM with parameter inheritance), and export parameters/diagnostics. Both are available as Docker apps; workflows emphasize configuration files, reports, and standard outputs to support transparency and reuse.
Difficulty level: Intermediate
Duration: 1:20:56
Speaker: : Granville Matheson

This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz

Course:
This module covers many of the types of non-invasive neurotech and neuroimaging devices including electroencephalography (EEG), electromyography (EMG), electroneurography (ENG), magnetoencephalography (MEG), and more.
Difficulty level: Beginner
Duration: 13:36
Speaker: : Harrison Canning

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This talk goes over Neurobagel, an open-source platform developed for improved dataset sharing and searching.
Difficulty level: Beginner
Duration: 13:37
Speaker: : Jean-Babtiste Poline

In this lesson, you will learn about the BRAIN Initiative Cell Atlas Network (BICAN) and how this project adopts a federated approach to data sharing.
Difficulty level: Beginner
Duration: 11:23
Speaker: : Owen White

In this second part of the lecture Data Science and Reproducibility, you will learn how to apply the awareness of the intersection between neuroscience and data science (discussed in part one) to an understanding of the current reproducibility crisis in biomedical science and neuroscience.
Difficulty level: Beginner
Duration: 31:31
Speaker: : Ashley Juavinett
This lecture covers the benefits and difficulties involved when re-using open datasets, and how metadata is important to the process.
Difficulty level: Beginner
Duration: 11:20
Speaker: : Elizabeth DuPre

This lesson provides a quick tour of some data repositories and how to download and manipulate data from them.
Difficulty level: Beginner
Duration: 00:49:06
Speaker: : Sebastian Urchs

Course:
KnowledgeSpace (KS) is a data discoverability portal and neuroscience encyclopedia that was developed to make it easier for the neuroscience community to find publicly available datasets that adhere to the FAIR Principles and to provide an integrated view of neuroscience concepts found in Wikipedia and NeuroLex linked with PubMed and 17 of the world's leading neuroscience repositories. In short, KS provides a single point of entry where reseaerchers can search for a neuroscience concept of interest and receive results that include: i. a description of the term found in Wikipedia/NeuroLex, ii. links to publicly available datasets related to the concept of interest, and iii. up-to-date references that support the concept of interests found in PubMed. APIs are available so that developers of other neuroscience research infrastructures can integrate KS components in their infrastructures. If your repository or your favorite repository is not indexed in KS, please contact us.
Difficulty level: Beginner
Duration: 6:14
Speaker: : Heather Topple

In this lesson, attendees will learn about the data structure standards, specifically the Brain Imaging Data Structure (BIDS), an INCF-endorsed standard for organizing, annotating, and describing data collected during neuroimaging experiments.
Difficulty level: Beginner
Duration: 21:56
Speaker: : Michael Schirner

This lecture explains the concept of federated analysis in the context of medical data, associated challenges. The lecture also presents an example of hospital federations via the Medical Informatics Platform.
Difficulty level: Intermediate
Duration: 19:15
Speaker: : Yannis Ioannidis

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This is a hands-on tutorial on PLINK, the open source whole genome association analysis toolset. The aims of this tutorial are to teach users how to perform basic quality control on genetic datasets, as well as to identify and understand GWAS summary statistics.
Difficulty level: Intermediate
Duration: 1:27:18
Speaker: : Dan Felsky

This is a tutorial on using the open-source software PRSice to calculate a set of polygenic risk scores (PRS) for a study sample. Users will also learn how to read PRS into R, visualize distributions, and perform basic association analyses.
Difficulty level: Intermediate
Duration: 1:53:34
Speaker: : Dan Felsky

This lesson is an overview of transcriptomics, from fundamental concepts of the central dogma and RNA sequencing at the single-cell level, to how genetic expression underlies diversity in cell phenotypes.
Difficulty level: Intermediate
Duration: 1:29:08
Speaker: : Shreejoy Tripathy