Lesson type
Difficulty level

Course:
The state of the field regarding the diagnosis and treatment of major depressive disorder (MDD) is discussed. Current challenges and opportunities facing the research and clinical communities are outlined, including appropriate quantitative and qualitative analyses of the heterogeneity of biological, social, and psychiatric factors which may contribute to MDD.
Difficulty level: Beginner
Duration: 1:29:28
Speaker: : Brett Jones, Victor Tang

This lesson gives a description of the BrainHealth Databank, a repository of many types of health-related data, whose aim is to accelerate research, improve care, and to help better understand and diagnose mental illness, as well as develop new treatments and prevention strategies.
This lesson corresponds to slides 46-78 of the PDF below.
Difficulty level: Beginner
Duration: 1:12:25
Speaker: : Joanna Yu

This lesson describes not only the need for precision medicine, but also the current state of the methods, pharmacogenetic approaches, utility and implementation of such care today.
This lesson corresponds to slides 1-50 of the PowerPoint below.
Difficulty level: Beginner
Duration: 1:24:30
Speaker: : Dan Felsky

This lecture discusses what defines an integrative approach regarding research and methods, including various study designs and models which are appropriate choices when attempting to bridge data domains; a necessity when whole-person modelling.
Difficulty level: Beginner
Duration: 1:28:14
Speaker: : Dan Felsky

Course:
This lecture introduces neuroscience concepts and methods such as fMRI, visual respones in BOLD data, and the eccentricity of visual receptive fields.
Difficulty level: Intermediate
Duration: 7:15
Speaker: : Mike X. Cohen

Course:
In this tutorial, users learn how to compute and visualize a t-test on experimental condition differences.
Difficulty level: Intermediate
Duration: 17:54
Speaker: : Mike X. Cohen

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This is a hands-on tutorial on PLINK, the open source whole genome association analysis toolset. The aims of this tutorial are to teach users how to perform basic quality control on genetic datasets, as well as to identify and understand GWAS summary statistics.
Difficulty level: Intermediate
Duration: 1:27:18
Speaker: : Dan Felsky

Course:
This video will document how to run a correlation analysis between the gray matter volume of two different structures using the output from brainlife app-freesurfer-stats.
Difficulty level: Beginner
Duration: 1:33
Speaker: :

As the previous lesson of this course described how researchers acquire neural data, this lesson will discuss how to go about interpreting and analysing the data.
Difficulty level: Intermediate
Duration: 9:24
Speaker: : Marcus Ghosh

In this lesson, you will learn about one particular aspect of decision making: reaction times. In other words, how long does it take to take a decision based on a stream of information arriving continuously over time?
Difficulty level: Intermediate
Duration: 6:01
Speaker: : Dan Goodman

Course:
Overview of the content for Day 1 of this course.
Difficulty level: Beginner
Duration: 00:01:59
Speaker: : Tristan Shuman

Course:
Overview of Day 2 of this course.
Difficulty level: Beginner
Duration: 00:03:28
Speaker: : Tristan Shuman

Course:
Best practices: the tips and tricks on how to get your Miniscope to work and how to get your experiments off the ground.
Difficulty level: Beginner
Duration: 00:53:34

Course:
This talk compares various sensors and resolutions for in vivo neural recordings.
Difficulty level: Beginner
Duration: 00:24:03
Speaker: : Susie Feng, Zach Pennington, Caleb Kemere
Course:
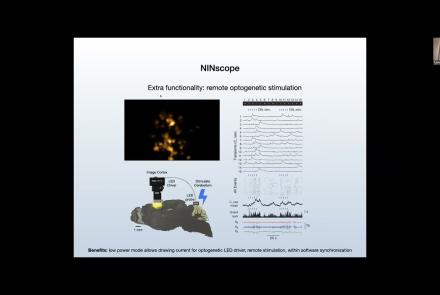
This talk delves into challenges and opportunities of Miniscope design, seeking the optimal balance between scale and function.
Difficulty level: Beginner
Duration: 00:21:51
Speaker: : Susie Feng, Zach Pennington, Tycho Hoogland

Course:
Attendees of this talk will learn aobut computational imaging systems and associated pipelines, as well as open-source software solutions supporting miniscope use.
Difficulty level: Beginner
Duration: 00:17:56
Speaker: : Susie Feng, Zach Pennington, Laura Waller

Course:
This talk covers the present state and future directions of calcium imaging data analysis, particularly in the context of one-photon vs two-photon approaches.
Difficulty level: Beginner
Duration: 00:21:06

Course:
In this talk, results from rodent experimentation using in vivo imaging are presented, demonstrating how the monitoring of neural ensembles may reveal patterns of learning during spatial tasks.
Difficulty level: Beginner
Duration: 00:19:43
Speaker: : Susie Feng, Zach Pennington, William Mau

Course:
How to start processing the raw imaging data generated with a Miniscope, including developing a usable pipeline and demoing the Minion pipeline.
Difficulty level: Beginner
Duration: 00:57:26
Speaker: : Daniel Aharoni, Phil Dong