Lesson type
Difficulty level

This lightning talk describes an automated pipline for positron emission tomography (PET) data.
Difficulty level: Intermediate
Duration: 7:27
Speaker: : Soodeh Moallemian
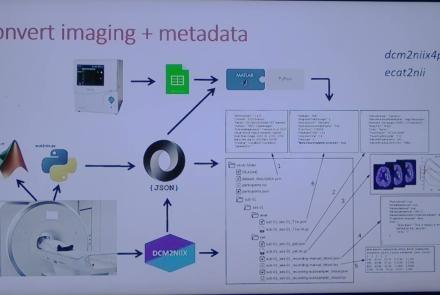
This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 9:23
Speaker: : Cyril Pernet

This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 41:04
Speaker: : Martin Nørgaard
This session dives into practical PET tooling on BIDS data—showing how to run motion correction, register PET↔MRI, extract time–activity curves, and generate standardized PET-BIDS derivatives with clear QC reports. It introduces modular BIDS Apps (head-motion correction, TAC extraction), a full pipeline (PETPrep), and a PET/MRI defacer, with guidance on parameters, outputs, provenance, and why Dockerized containers are the reliable way to run them at scale.
Difficulty level: Intermediate
Duration: 1:05:38
Speaker: : Martin Nørgaard

This session introduces two PET quantification tools—bloodstream for processing arterial blood data and kinfitr for kinetic modeling and quantification—built to work with BIDS/BIDS-derivatives and containers. Bloodstream fuses autosampler and manual measurements (whole blood, plasma, parent fraction) using interpolation or fitted models (incl. hierarchical GAMs) to produce a clean arterial input function (AIF) and whole-blood curves with rich QC reports ready. TAC data (e.g., from PETPrep) and blood (e.g., from bloodstream) can be ingested using kinfitr to run reproducible, GUI-driven analyses: define combined ROIs, calculate weighting factors, estimate blood–tissue delay, choose and chain models (e.g., 2TCM → 1TCM with parameter inheritance), and export parameters/diagnostics. Both are available as Docker apps; workflows emphasize configuration files, reports, and standard outputs to support transparency and reuse.
Difficulty level: Intermediate
Duration: 1:20:56
Speaker: : Granville Matheson

This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz

Course:
This module covers many of the types of non-invasive neurotech and neuroimaging devices including electroencephalography (EEG), electromyography (EMG), electroneurography (ENG), magnetoencephalography (MEG), and more.
Difficulty level: Beginner
Duration: 13:36
Speaker: : Harrison Canning

This is the first of two workshops on reproducibility in science, during which participants are introduced to concepts of FAIR and open science. After discussing the definition of and need for FAIR science, participants are walked through tutorials on installing and using Github and Docker, the powerful, open-source tools for versioning and publishing code and software, respectively.
Difficulty level: Intermediate
Duration: 1:20:58
Speaker: : Erin Dickie and Sejal Patel

Course:
In this lesson, while learning about the need for increased large-scale collaborative science that is transparent in nature, users also are given a tutorial on using Synapse for facilitating reusable and reproducible research.
Difficulty level: Beginner
Duration: 1:15:12
Speaker: : Abhi Pratap

This lesson contains the first part of the lecture Data Science and Reproducibility. You will learn about the development of data science and what the term currently encompasses, as well as how neuroscience and data science intersect.
Difficulty level: Beginner
Duration: 32:18
Speaker: : Ariel Rokem

In this second part of the lecture Data Science and Reproducibility, you will learn how to apply the awareness of the intersection between neuroscience and data science (discussed in part one) to an understanding of the current reproducibility crisis in biomedical science and neuroscience.
Difficulty level: Beginner
Duration: 31:31
Speaker: : Ashley Juavinett

Course:
The lecture provides an overview of the core skills and practical solutions required to practice reproducible research.
Difficulty level: Beginner
Duration: 1:25:17
Speaker: : Fernando Perez

Course:
This lecture provides an introduction to reproducibility issues within the fields of neuroimaging and fMRI, as well as an overview of tools and resources being developed to alleviate the problem.
Difficulty level: Beginner
Duration: 1:03:07
Speaker: : Russell Poldrack

Course:
This lecture provides a historical perspective on reproducibility in science, as well as the current limitations of neuroimaging studies to date. This lecture also lays out a case for the use of meta-analyses, outlining available resources to conduct such analyses.
Difficulty level: Beginner
Duration: 55:39
Speaker: : Angela Laird

This workshop will introduce reproducible workflows and a range of tools along the themes of organisation, documentation, analysis, and dissemination.
Difficulty level: Beginner
Duration: 01:28:43
Speaker: :
Course:
This book was written with the goal of introducing researchers and students in a variety of research fields to the intersection of data science and neuroimaging. This book reflects our own experience of doing research at the intersection of data science and neuroimaging and it is based on our experience working with students and collaborators who come from a variety of backgrounds and have a variety of reasons for wanting to use data science approaches in their work. The tools and ideas that we chose to write about are all tools and ideas that we have used in some way in our own research. Many of them are tools that we use on a daily basis in our work. This was important to us for a few reasons: the first is that we want to teach people things that we ourselves find useful. Second, it allowed us to write the book with a focus on solving specific analysis tasks. For example, in many of the chapters you will see that we walk you through ideas while implementing them in code, and with data. We believe that this is a good way to learn about data analysis, because it provides a connecting thread from scientific questions through the data and its representation to implementing specific answers to these questions. Finally, we find these ideas compelling and fruitful. That’s why we were drawn to them in the first place. We hope that our enthusiasm about the ideas and tools described in this book will be infectious enough to convince the readers of their value.
Difficulty level: Intermediate
Duration:
Speaker: :