Lesson type
Difficulty level

This lecture covers different perspectives on the study of the mental, focusing on the difference between Mind and Brain.
Difficulty level: Beginner
Duration: 1:16:30
Speaker: : Paul F.M.J. Verschure

This lesson briefly goes over the outline of the Neuroscience for Machine Learners course.
Difficulty level: Intermediate
Duration: 3:05
Speaker: : Dan Goodman

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

This tutorial covers the fundamentals of collaborating with Git and GitHub.
Difficulty level: Intermediate
Duration: 2:15:50
Speaker: : Elizabeth DuPre

Course:
This lesson provides a comprehensive introduction to the command line and 50 popular Linux commands. This is a long introduction (nearly 5 hours), but well worth it if you are going to spend a good part of your career working from a terminal, which is likely if you are interested in flexibility, power, and reproducibility in neuroscience research. This lesson is courtesy of freeCodeCamp.
Difficulty level: Beginner
Duration: 5:00:16
Speaker: : Colt Steele

Course:
This lesson describes the principles underlying functional magnetic resonance imaging (fMRI), diffusion-weighted imaging (DWI), tractography, and parcellation. These tools and concepts are explained in a broader context of neural connectivity and mental health.
Difficulty level: Intermediate
Duration: 1:47:22
Speaker: : Erin Dickie and John Griffiths

Course:
This tutorial introduces pipelines and methods to compute brain connectomes from fMRI data. With corresponding code and repositories, participants can follow along and learn how to programmatically preprocess, curate, and analyze functional and structural brain data to produce connectivity matrices.
Difficulty level: Intermediate
Duration: 1:39:04
Speaker: : Erin Dickie and John Griffiths

This lesson introduces the practical exercises which accompany the previous lessons on animal and human connectomes in the brain and nervous system.
Difficulty level: Intermediate
Duration: 4:10
Speaker: : Dan Goodman

Course:
This lecture and tutorial focuses on measuring human functional brain networks, as well as how to account for inherent variability within those networks.
Difficulty level: Intermediate
Duration: 50:44
Speaker: : Caterina Gratton

Course:
This lecture presents an overview of functional brain parcellations, as well as a set of tutorials on bootstrap agregation of stable clusters (BASC) for fMRI brain parcellation.
Difficulty level: Advanced
Duration: 50:28
Speaker: : Pierre Bellec

Course:
This lecture covers FAIR atlases, including their background and construction, as well as how they can be created in line with the FAIR principles.
Difficulty level: Beginner
Duration: 14:24
Speaker: : Heidi Kleven

This lecture covers the IBI Data Standards and Sharing Working Group, including its history, aims, and projects.
Difficulty level: Beginner
Duration: 3:58
Speaker: : Kenji Doya
This session covers the framework of the International Brain Lab (IBL) and the data architecture used for this project.
Difficulty level: Beginner
Duration: 23:37
Speaker: : Kenneth Harris
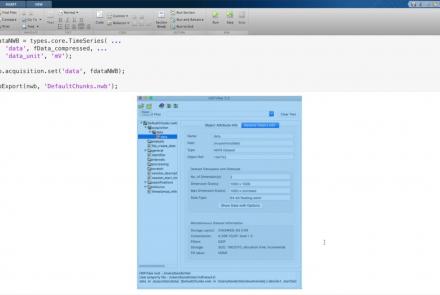
This lesson provides a tutorial on how to handle writing very large data in MatNWB.
Difficulty level: Advanced
Duration: 16:18
Speaker: : Ben Dichter

This lesson provides an overview of the CaImAn package, as well as a demonstration of usage with NWB.
Difficulty level: Intermediate
Duration: 44:37
Speaker: : Andrea Giovannucci

This lesson gives an overview of the SpikeInterface package, including demonstration of data loading, preprocessing, spike sorting, and comparison of spike sorters.
Difficulty level: Intermediate
Duration: 1:10:28
Speaker: : Alessio Buccino

In this lesson, users will learn about the NWBWidgets package, including coverage of different data types, and information for building custom widgets within this framework.
Difficulty level: Intermediate
Duration: 47:15
Speaker: : Ben Dichter

This lecture provides reviews some standards for project management and organization, including motivation from the view of the FAIR principles and improved reproducibility.
Difficulty level: Beginner
Duration: 01:08:34
Speaker: : Elizabeth DuPre

This lesson breaks down the principles of Bayesian inference and how it relates to cognitive processes and functions like learning and perception. It is then explained how cognitive models can be built using Bayesian statistics in order to investigate how our brains interface with their environment.
This lesson corresponds to slides 1-64 in the PDF below.
Difficulty level: Intermediate
Duration: 1:28:14
Speaker: : Andreea Diaconescu

This is a tutorial on designing a Bayesian inference model to map belief trajectories, with emphasis on gaining familiarity with Hierarchical Gaussian Filters (HGFs).
This lesson corresponds to slides 65-90 of the PDF below.
Difficulty level: Intermediate
Duration: 1:15:04
Speaker: : Daniel Hauke