Lesson type
Difficulty level

This is the first of two workshops on reproducibility in science, during which participants are introduced to concepts of FAIR and open science. After discussing the definition of and need for FAIR science, participants are walked through tutorials on installing and using Github and Docker, the powerful, open-source tools for versioning and publishing code and software, respectively.
Difficulty level: Intermediate
Duration: 1:20:58
Speaker: : Erin Dickie and Sejal Patel

Course:
In this lesson, while learning about the need for increased large-scale collaborative science that is transparent in nature, users also are given a tutorial on using Synapse for facilitating reusable and reproducible research.
Difficulty level: Beginner
Duration: 1:15:12
Speaker: : Abhi Pratap

This lesson contains the first part of the lecture Data Science and Reproducibility. You will learn about the development of data science and what the term currently encompasses, as well as how neuroscience and data science intersect.
Difficulty level: Beginner
Duration: 32:18
Speaker: : Ariel Rokem

In this second part of the lecture Data Science and Reproducibility, you will learn how to apply the awareness of the intersection between neuroscience and data science (discussed in part one) to an understanding of the current reproducibility crisis in biomedical science and neuroscience.
Difficulty level: Beginner
Duration: 31:31
Speaker: : Ashley Juavinett

Course:
The lecture provides an overview of the core skills and practical solutions required to practice reproducible research.
Difficulty level: Beginner
Duration: 1:25:17
Speaker: : Fernando Perez

Course:
This lecture provides an introduction to reproducibility issues within the fields of neuroimaging and fMRI, as well as an overview of tools and resources being developed to alleviate the problem.
Difficulty level: Beginner
Duration: 1:03:07
Speaker: : Russell Poldrack

Course:
This lecture provides a historical perspective on reproducibility in science, as well as the current limitations of neuroimaging studies to date. This lecture also lays out a case for the use of meta-analyses, outlining available resources to conduct such analyses.
Difficulty level: Beginner
Duration: 55:39
Speaker: : Angela Laird

This workshop will introduce reproducible workflows and a range of tools along the themes of organisation, documentation, analysis, and dissemination.
Difficulty level: Beginner
Duration: 01:28:43
Speaker: :

This lesson breaks down the principles of Bayesian inference and how it relates to cognitive processes and functions like learning and perception. It is then explained how cognitive models can be built using Bayesian statistics in order to investigate how our brains interface with their environment.
This lesson corresponds to slides 1-64 in the PDF below.
Difficulty level: Intermediate
Duration: 1:28:14
Speaker: : Andreea Diaconescu

This is a tutorial on designing a Bayesian inference model to map belief trajectories, with emphasis on gaining familiarity with Hierarchical Gaussian Filters (HGFs).
This lesson corresponds to slides 65-90 of the PDF below.
Difficulty level: Intermediate
Duration: 1:15:04
Speaker: : Daniel Hauke

This tutorial walks participants through the application of dynamic causal modelling (DCM) to fMRI data using MATLAB. Participants are also shown various forms of DCM, how to generate and specify different models, and how to fit them to simulated neural and BOLD data.
This lesson corresponds to slides 158-187 of the PDF below.
Difficulty level: Advanced
Duration: 1:22:10
Speaker: : Peter Bedford, Povilas Karvelis

This lesson contains practical exercises which accompanies the first few lessons of the Neuroscience for Machine Learners (Neuro4ML) course.
Difficulty level: Intermediate
Duration: 5:58
Speaker: : Dan Goodman

This video briefly goes over the exercises accompanying Week 6 of the Neuroscience for Machine Learners (Neuro4ML) course, Understanding Neural Networks.
Difficulty level: Intermediate
Duration: 2:43
Speaker: : Marcus Ghosh

Course:
This lecture covers the description and characterization of an input-output relationship in a information-theoretic context.
Difficulty level: Beginner
Duration: 1:35:33
Speaker: : Jonathan D. Victor

This lesson is part 1 of 2 of a tutorial on statistical models for neural data.
Difficulty level: Beginner
Duration: 1:45:48
Speaker: : Jonathan Pillow
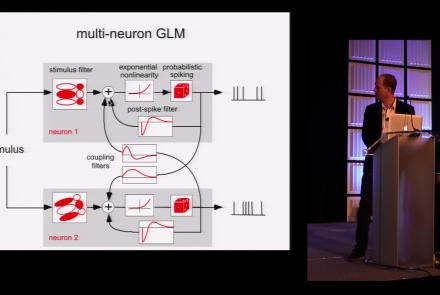
This lesson is part 2 of 2 of a tutorial on statistical models for neural data.
Difficulty level: Beginner
Duration: 1:50:31
Speaker: : Jonathan Pillow

Course:
This lesson provides an introduction to modeling single neurons, as well as stability analysis of neural models.
Difficulty level: Intermediate
Duration: 1:26:06
Speaker: : Bard Ermentrout

Course:
This lesson continues a thorough description of the concepts, theories, and methods involved in the modeling of single neurons.
Difficulty level: Intermediate
Duration: 1:25:38
Speaker: : Bard Ermentrout

Course:
In this lesson you will learn about fundamental neural phenomena such as oscillations and bursting, and the effects these have on cortical networks.
Difficulty level: Intermediate
Duration: 1:24:30
Speaker: : Bard Ermentrout

Course:
This lesson continues discussing properties of neural oscillations and networks.
Difficulty level: Intermediate
Duration: 1:31:57
Speaker: : Bard Ermentrout