Lesson type
Difficulty level

Course:
The Mouse Phenome Database (MPD) provides access to primary experimental trait data, genotypic variation, protocols and analysis tools for mouse genetic studies. Data are contributed by investigators worldwide and represent a broad scope of phenotyping endpoints and disease-related traits in naïve mice and those exposed to drugs, environmental agents or other treatments. MPD ensures rigorous curation of phenotype data and supporting documentation using relevant ontologies and controlled vocabularies. As a repository of curated and integrated data, MPD provides a means to access/re-use baseline data, as well as allows users to identify sensitized backgrounds for making new mouse models with genome editing technologies, analyze trait co-inheritance, benchmark assays in their own laboratories, and many other research applications. MPD’s primary source of funding is NIDA. For this reason, a majority of MPD data is neuro- and behavior-related.
Difficulty level: Beginner
Duration: 55:36
Speaker: : Elissa Chesler

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This talk goes over Neurobagel, an open-source platform developed for improved dataset sharing and searching.
Difficulty level: Beginner
Duration: 13:37
Speaker: : Jean-Babtiste Poline

In this lesson, you will learn about the BRAIN Initiative Cell Atlas Network (BICAN) and how this project adopts a federated approach to data sharing.
Difficulty level: Beginner
Duration: 11:23
Speaker: : Owen White

In this second part of the lecture Data Science and Reproducibility, you will learn how to apply the awareness of the intersection between neuroscience and data science (discussed in part one) to an understanding of the current reproducibility crisis in biomedical science and neuroscience.
Difficulty level: Beginner
Duration: 31:31
Speaker: : Ashley Juavinett

This lecture covers the benefits and difficulties involved when re-using open datasets, and how metadata is important to the process.
Difficulty level: Beginner
Duration: 11:20
Speaker: : Elizabeth DuPre

This lesson provides a quick tour of some data repositories and how to download and manipulate data from them.
Difficulty level: Beginner
Duration: 00:49:06
Speaker: : Sebastian Urchs

Course:
KnowledgeSpace (KS) is a data discoverability portal and neuroscience encyclopedia that was developed to make it easier for the neuroscience community to find publicly available datasets that adhere to the FAIR Principles and to provide an integrated view of neuroscience concepts found in Wikipedia and NeuroLex linked with PubMed and 17 of the world's leading neuroscience repositories. In short, KS provides a single point of entry where reseaerchers can search for a neuroscience concept of interest and receive results that include: i. a description of the term found in Wikipedia/NeuroLex, ii. links to publicly available datasets related to the concept of interest, and iii. up-to-date references that support the concept of interests found in PubMed. APIs are available so that developers of other neuroscience research infrastructures can integrate KS components in their infrastructures. If your repository or your favorite repository is not indexed in KS, please contact us.
Difficulty level: Beginner
Duration: 6:14
Speaker: : Heather Topple

In this lesson, attendees will learn about the data structure standards, specifically the Brain Imaging Data Structure (BIDS), an INCF-endorsed standard for organizing, annotating, and describing data collected during neuroimaging experiments.
Difficulty level: Beginner
Duration: 21:56
Speaker: : Michael Schirner

Course:
This lesson is a general overview of overarching concepts in neuroinformatics research, with a particular focus on clinical approaches to defining, measuring, studying, diagnosing, and treating various brain disorders. Also described are the complex, multi-level nature of brain disorders and the data associated with them, from genes and individual cells up to cortical microcircuits and whole-brain network dynamics. Given the heterogeneity of brain disorders and their underlying mechanisms, this lesson lays out a case for multiscale neuroscience data integration.
Difficulty level: Intermediate
Duration: 1:09:33
Speaker: : Sean Hill

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman

This is a continuation of the talk on the cellular mechanisms of neuronal communication, this time at the level of brain microcircuits and associated global signals like those measureable by electroencephalography (EEG). This lecture also discusses EEG biomarkers in mental health disorders, and how those cortical signatures may be simulated digitally.
Difficulty level: Intermediate
Duration: 1:11:04
Speaker: : Etay Hay

This is the second of three lectures around current challenges and opportunities facing neuroinformatic infrastructure for handling sensitive data.
Difficulty level: Beginner
Duration: 48:26
Speaker: : Michael Schirner

In this lesson you will learn about current efforts towards integrating multimodal human brain data using the open source SCORE HED library schema.
Difficulty level: Beginner
Duration: 23:29
Speaker: : Dora Hermes

This lecture aims to help researchers, students, and health care professionals understand the place for neuroinformatics in the patient journey using the exemplar of an epilepsy patient.
Difficulty level: Intermediate
Duration: 1:32:53
Speaker: : Randy Gollub & Prantik Kundu

The lesson introduces the Brain Imaging Data Structure (BIDS), the community standard for organizing, curating, and sharing neuroimaging and associated data. The session focuses on understanding the BIDS framework, learning its data structure and validation processes.
Difficulty level: Intermediate
Duration: 38:52
Speaker: : Cyril Pernet

This session moves from BIDS basics into analysis workflows, focusing on how to turn raw, BIDS-organized data into derivatives using BIDS Apps and containers for reproducible processing. It compares end-to-end pipelines across fMRI and PET (and notes EEG/MEG), explains typical preprocessing choices, and shows how standardized inputs plus containerized tools (Docker/AppTainer) yield consistent, auditable outputs.
Difficulty level: Intermediate
Duration: 56:03
Speaker: : Martin Nørgaard

The session explains GDPR rules around data sharing for research in Europe, the distinction between law and ethics, and introduces practical solutions for securely sharing sensitive datasets. Researchers have more flexibility than commonly assumed: scientific research is considered a public interest task, so explicit consent for data sharing isn’t legally required, though transparency and informing participants remain ethically important. The talk also introduces publicneuro.eu, a controlled-access platform that enables sharing neuroimaging datasets with open metadata, DOIs, and customizable access restrictions while ensuring GDPR compliance.
Difficulty level: Intermediate
Duration: 31:12
Speaker: : Cyril Pernet
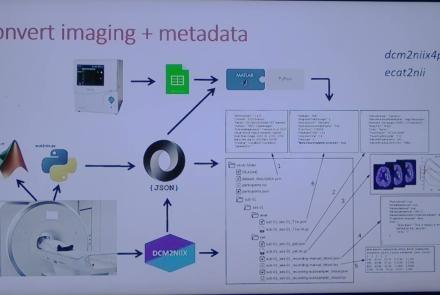
This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 9:23
Speaker: : Cyril Pernet

This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 41:04
Speaker: : Martin Nørgaard