Lesson type
Difficulty level

This lecture describes how to build research workflows, including a demonstrate using DataJoint Elements to build data pipelines.
Difficulty level: Intermediate
Duration: 47:00
Speaker: : Dimitri Yatsenko

This lesson provides an introduction to the Symposium on Science Management at the Canadian Association for Neuroscience 2019 Meeting.
Difficulty level: Beginner
Duration: 9:52
Speaker: : Randy McIntosh

This lesson gives a primer to project management in a scientific context, with a particular neuroinformatic case study.
Difficulty level: Beginner
Duration: 19:06
Speaker: : Kelly Shen

In this lesson, you will hear about the current challenges regarding data management, as well as policies and resources aimed to address them.
Difficulty level: Beginner
Duration: 18:13
Speaker: : Mojib Javadi

This lesson covers "Knowledge Translation", the activities involved in moving research from the laboratory, the research journal, and the academic conference into the hands of people and organizations who can put it to practical use.
Difficulty level: Beginner
Duration: 15:05
Speaker: : Jordan Antflick

In this lesson, you will hear about the various methods developed and employed in managing performance.
Difficulty level: Beginner
Duration: 12:57
Speaker: : Christa Studzinski

This lesson provides an overview of how to manage relationships in a research context, while highlighting the need for effective communication at various levels.
Difficulty level: Beginner
Duration:
Speaker: : Helena Ledmyr

In this lesson you will hear a panel discussion which hosts experts in the field whom have extensive experience with management in a science setting.
Difficulty level: Beginner
Duration: 54:38
Speaker: :

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This talk goes over Neurobagel, an open-source platform developed for improved dataset sharing and searching.
Difficulty level: Beginner
Duration: 13:37
Speaker: : Jean-Babtiste Poline

In this lesson, you will learn about the BRAIN Initiative Cell Atlas Network (BICAN) and how this project adopts a federated approach to data sharing.
Difficulty level: Beginner
Duration: 11:23
Speaker: : Owen White

In this second part of the lecture Data Science and Reproducibility, you will learn how to apply the awareness of the intersection between neuroscience and data science (discussed in part one) to an understanding of the current reproducibility crisis in biomedical science and neuroscience.
Difficulty level: Beginner
Duration: 31:31
Speaker: : Ashley Juavinett

This lecture covers the benefits and difficulties involved when re-using open datasets, and how metadata is important to the process.
Difficulty level: Beginner
Duration: 11:20
Speaker: : Elizabeth DuPre

This lesson provides a quick tour of some data repositories and how to download and manipulate data from them.
Difficulty level: Beginner
Duration: 00:49:06
Speaker: : Sebastian Urchs

Course:
KnowledgeSpace (KS) is a data discoverability portal and neuroscience encyclopedia that was developed to make it easier for the neuroscience community to find publicly available datasets that adhere to the FAIR Principles and to provide an integrated view of neuroscience concepts found in Wikipedia and NeuroLex linked with PubMed and 17 of the world's leading neuroscience repositories. In short, KS provides a single point of entry where reseaerchers can search for a neuroscience concept of interest and receive results that include: i. a description of the term found in Wikipedia/NeuroLex, ii. links to publicly available datasets related to the concept of interest, and iii. up-to-date references that support the concept of interests found in PubMed. APIs are available so that developers of other neuroscience research infrastructures can integrate KS components in their infrastructures. If your repository or your favorite repository is not indexed in KS, please contact us.
Difficulty level: Beginner
Duration: 6:14
Speaker: : Heather Topple

In this lesson, attendees will learn about the data structure standards, specifically the Brain Imaging Data Structure (BIDS), an INCF-endorsed standard for organizing, annotating, and describing data collected during neuroimaging experiments.
Difficulty level: Beginner
Duration: 21:56
Speaker: : Michael Schirner

The lesson introduces the Brain Imaging Data Structure (BIDS), the community standard for organizing, curating, and sharing neuroimaging and associated data. The session focuses on understanding the BIDS framework, learning its data structure and validation processes.
Difficulty level: Intermediate
Duration: 38:52
Speaker: : Cyril Pernet

This session moves from BIDS basics into analysis workflows, focusing on how to turn raw, BIDS-organized data into derivatives using BIDS Apps and containers for reproducible processing. It compares end-to-end pipelines across fMRI and PET (and notes EEG/MEG), explains typical preprocessing choices, and shows how standardized inputs plus containerized tools (Docker/AppTainer) yield consistent, auditable outputs.
Difficulty level: Intermediate
Duration: 56:03
Speaker: : Martin Nørgaard

The session explains GDPR rules around data sharing for research in Europe, the distinction between law and ethics, and introduces practical solutions for securely sharing sensitive datasets. Researchers have more flexibility than commonly assumed: scientific research is considered a public interest task, so explicit consent for data sharing isn’t legally required, though transparency and informing participants remain ethically important. The talk also introduces publicneuro.eu, a controlled-access platform that enables sharing neuroimaging datasets with open metadata, DOIs, and customizable access restrictions while ensuring GDPR compliance.
Difficulty level: Intermediate
Duration: 31:12
Speaker: : Cyril Pernet
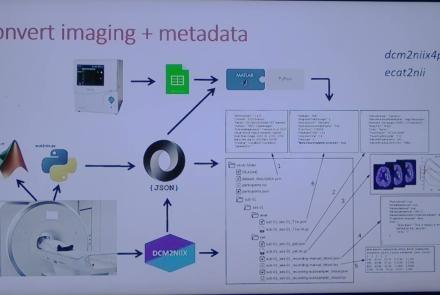
This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 9:23
Speaker: : Cyril Pernet