Lesson type
Difficulty level

This lesson consists of lecture and tutorial components, focusing on resources and tools which facilitate multi-scale brain modeling and simulation.
Difficulty level: Beginner
Duration: 3:46:21
Speaker: : Dionysios Perdikis

In this talk, challenges of handling complex neuroscientific data are discussed, as well as tools and services for the annotation, organization, storage, and sharing of these data.
Difficulty level: Beginner
Duration: 21:49
Speaker: : Thomas Wachtler

This lecture describes the neuroscience data respository G-Node Infrastructure (GIN), which provides platform independent data access and enables easy data publishing.
Difficulty level: Beginner
Duration: 22:23
Speaker: : Michael Sonntag

This lesson provides an introduction to the course Neuroscience Data Integration Through Use of Digital Brain Atlases, during which attendees will learn about concepts for integration of research data, approaches and resources for assigning anatomical location to brain data, and infrastructure for sharing experimental brain research data.
Difficulty level: Beginner
Duration: 14:02
Speaker: : Trygve Leergard

This talk covers the various concepts, motivations, and trends within the neuroscientific community related to the sharing and integration of brain research data.
Difficulty level: Beginner
Duration: 30:39
Speaker: : Jan G. Bjaalie

This lesson focuses on the neuroanatomy of the human brain, delving into macrostructures like cortices, lobes, and hemispheres, and microstructures like neurons and cortical laminae.
Difficulty level: Beginner
Duration: 51:30
Speaker: : Nicola Palomero-Gallagher

This lesson provides an introduction to the European open research infrastructure EBRAINS and its digital brain atlas resources.
Difficulty level: Beginner
Duration: 27:45
Speaker: : Trygve Leergard

In this lesson, attendees will learn about the challenges in assigning experimental brain data to specific locations, as well as the advantages and shortcomings of current location assignment procedures.
Difficulty level: Beginner
Duration: 32:18
Speaker: : Ingvild Elise Bjerke

This lesson covers the inherent difficulties associated with integrating neuroscientific data, as well as the current methods and approaches to do so.
Difficulty level: Beginner
Duration: 25:41
Speaker: : Trygve Leergard

Attendees of this talk will learn about QuickNII, a tool for user-guided affine registration of 2D experimental image data to 3D atlas reference spaces, which also facilitates data integration through standardized coordinate systems.
Difficulty level: Beginner
Duration: 21:08
Speaker: : Maja Puchades

This lesson provides an overview of DeepSlice, a Python package which aligns histology to the Allen Brain Atlas and Waxholm Rat Atlas using deep learning.
Difficulty level: Beginner
Duration: 17:30
Speaker: : Harry Carey

The lesson introduces the Brain Imaging Data Structure (BIDS), the community standard for organizing, curating, and sharing neuroimaging and associated data. The session focuses on understanding the BIDS framework, learning its data structure and validation processes.
Difficulty level: Intermediate
Duration: 38:52
Speaker: : Cyril Pernet

This session moves from BIDS basics into analysis workflows, focusing on how to turn raw, BIDS-organized data into derivatives using BIDS Apps and containers for reproducible processing. It compares end-to-end pipelines across fMRI and PET (and notes EEG/MEG), explains typical preprocessing choices, and shows how standardized inputs plus containerized tools (Docker/AppTainer) yield consistent, auditable outputs.
Difficulty level: Intermediate
Duration: 56:03
Speaker: : Martin Nørgaard

The session explains GDPR rules around data sharing for research in Europe, the distinction between law and ethics, and introduces practical solutions for securely sharing sensitive datasets. Researchers have more flexibility than commonly assumed: scientific research is considered a public interest task, so explicit consent for data sharing isn’t legally required, though transparency and informing participants remain ethically important. The talk also introduces publicneuro.eu, a controlled-access platform that enables sharing neuroimaging datasets with open metadata, DOIs, and customizable access restrictions while ensuring GDPR compliance.
Difficulty level: Intermediate
Duration: 31:12
Speaker: : Cyril Pernet
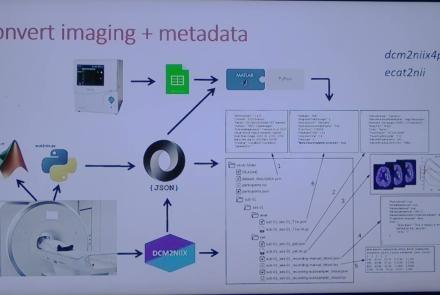
This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 9:23
Speaker: : Cyril Pernet

This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 41:04
Speaker: : Martin Nørgaard
This session dives into practical PET tooling on BIDS data—showing how to run motion correction, register PET↔MRI, extract time–activity curves, and generate standardized PET-BIDS derivatives with clear QC reports. It introduces modular BIDS Apps (head-motion correction, TAC extraction), a full pipeline (PETPrep), and a PET/MRI defacer, with guidance on parameters, outputs, provenance, and why Dockerized containers are the reliable way to run them at scale.
Difficulty level: Intermediate
Duration: 1:05:38
Speaker: : Martin Nørgaard

This session introduces two PET quantification tools—bloodstream for processing arterial blood data and kinfitr for kinetic modeling and quantification—built to work with BIDS/BIDS-derivatives and containers. Bloodstream fuses autosampler and manual measurements (whole blood, plasma, parent fraction) using interpolation or fitted models (incl. hierarchical GAMs) to produce a clean arterial input function (AIF) and whole-blood curves with rich QC reports ready. TAC data (e.g., from PETPrep) and blood (e.g., from bloodstream) can be ingested using kinfitr to run reproducible, GUI-driven analyses: define combined ROIs, calculate weighting factors, estimate blood–tissue delay, choose and chain models (e.g., 2TCM → 1TCM with parameter inheritance), and export parameters/diagnostics. Both are available as Docker apps; workflows emphasize configuration files, reports, and standard outputs to support transparency and reuse.
Difficulty level: Intermediate
Duration: 1:20:56
Speaker: : Granville Matheson

Learn how to create a standard extracellular electrophysiology dataset in NWB using Python.
Difficulty level: Intermediate
Duration: 23:10
Speaker: : Ryan Ly

Learn how to create a standard calcium imaging dataset in NWB using Python.
Difficulty level: Intermediate
Duration: 31:04
Speaker: : Ryan Ly