Lesson type
Difficulty level

In this lesson you will learn how machine learners and neuroscientists construct abstract computational models based on various neurophysiological signalling properties.
Difficulty level: Intermediate
Duration: 10:52
Speaker: : Dan Goodman

In this lesson, you will learn about some typical neuronal models employed by machine learners and computational neuroscientists, meant to imitate the biophysical properties of real neurons.
Difficulty level: Intermediate
Duration: 3:12
Speaker: : Dan Goodman

Whereas the previous two lessons described the biophysical and signalling properties of individual neurons, this lesson describes properties of those units when part of larger networks.
Difficulty level: Intermediate
Duration: 6:00
Speaker: : Marcus Ghosh

This lesson goes over some examples of how machine learners and computational neuroscientists go about designing and building neural network models inspired by biological brain systems.
Difficulty level: Intermediate
Duration: 12:52
Speaker: : Dan Goodman

In this lesson, you will learn about different approaches to modeling learning in neural networks, particularly focusing on system parameters such as firing rates and synaptic weights impact a network.
Difficulty level: Intermediate
Duration: 9:40
Speaker: : Dan Goodman

In this lesson, you will learn more about some of the issues inherent in modeling neural spikes, approaches to ameliorate these problems, and the pros and cons of these approaches.
Difficulty level: Intermediate
Duration: 5:31
Speaker: : Dan Goodman

In this lesson, you will learn about some of the many methods to train spiking neural networks (SNNs) with either no attempt to use gradients, or only use gradients in a limited or constrained way.
Difficulty level: Intermediate
Duration: 5:14
Speaker: : Dan Goodman

In this lesson, you will learn how to train spiking neural networks (SNNs) with a surrogate gradient method.
Difficulty level: Intermediate
Duration: 11:23
Speaker: : Dan Goodman

This lesson explores how researchers try to understand neural networks, particularly in the case of observing neural activity.
Difficulty level: Intermediate
Duration: 8:20
Speaker: : Marcus Ghosh

In this lesson you will learn about the motivation behind manipulating neural activity, and what forms that may take in various experimental designs.
Difficulty level: Intermediate
Duration: 8:42
Speaker: : Marcus Ghosh

This video briefly goes over the exercises accompanying Week 6 of the Neuroscience for Machine Learners (Neuro4ML) course, Understanding Neural Networks.
Difficulty level: Intermediate
Duration: 2:43
Speaker: : Marcus Ghosh

The lesson introduces the Brain Imaging Data Structure (BIDS), the community standard for organizing, curating, and sharing neuroimaging and associated data. The session focuses on understanding the BIDS framework, learning its data structure and validation processes.
Difficulty level: Intermediate
Duration: 38:52
Speaker: : Cyril Pernet

This session moves from BIDS basics into analysis workflows, focusing on how to turn raw, BIDS-organized data into derivatives using BIDS Apps and containers for reproducible processing. It compares end-to-end pipelines across fMRI and PET (and notes EEG/MEG), explains typical preprocessing choices, and shows how standardized inputs plus containerized tools (Docker/AppTainer) yield consistent, auditable outputs.
Difficulty level: Intermediate
Duration: 56:03
Speaker: : Martin Nørgaard

The session explains GDPR rules around data sharing for research in Europe, the distinction between law and ethics, and introduces practical solutions for securely sharing sensitive datasets. Researchers have more flexibility than commonly assumed: scientific research is considered a public interest task, so explicit consent for data sharing isn’t legally required, though transparency and informing participants remain ethically important. The talk also introduces publicneuro.eu, a controlled-access platform that enables sharing neuroimaging datasets with open metadata, DOIs, and customizable access restrictions while ensuring GDPR compliance.
Difficulty level: Intermediate
Duration: 31:12
Speaker: : Cyril Pernet
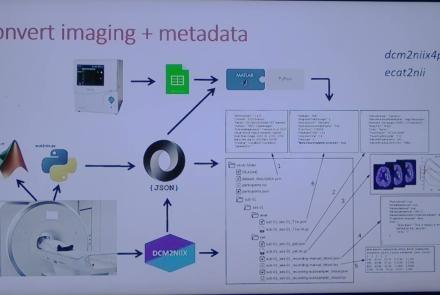
This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 9:23
Speaker: : Cyril Pernet

This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 41:04
Speaker: : Martin Nørgaard
This session dives into practical PET tooling on BIDS data—showing how to run motion correction, register PET↔MRI, extract time–activity curves, and generate standardized PET-BIDS derivatives with clear QC reports. It introduces modular BIDS Apps (head-motion correction, TAC extraction), a full pipeline (PETPrep), and a PET/MRI defacer, with guidance on parameters, outputs, provenance, and why Dockerized containers are the reliable way to run them at scale.
Difficulty level: Intermediate
Duration: 1:05:38
Speaker: : Martin Nørgaard

This session introduces two PET quantification tools—bloodstream for processing arterial blood data and kinfitr for kinetic modeling and quantification—built to work with BIDS/BIDS-derivatives and containers. Bloodstream fuses autosampler and manual measurements (whole blood, plasma, parent fraction) using interpolation or fitted models (incl. hierarchical GAMs) to produce a clean arterial input function (AIF) and whole-blood curves with rich QC reports ready. TAC data (e.g., from PETPrep) and blood (e.g., from bloodstream) can be ingested using kinfitr to run reproducible, GUI-driven analyses: define combined ROIs, calculate weighting factors, estimate blood–tissue delay, choose and chain models (e.g., 2TCM → 1TCM with parameter inheritance), and export parameters/diagnostics. Both are available as Docker apps; workflows emphasize configuration files, reports, and standard outputs to support transparency and reuse.
Difficulty level: Intermediate
Duration: 1:20:56
Speaker: : Granville Matheson

Learn how to create a standard extracellular electrophysiology dataset in NWB using Python.
Difficulty level: Intermediate
Duration: 23:10
Speaker: : Ryan Ly

Learn how to create a standard calcium imaging dataset in NWB using Python.
Difficulty level: Intermediate
Duration: 31:04
Speaker: : Ryan Ly