Lesson type
Difficulty level

This lesson provides an overview of how to conceptualize, design, implement, and maintain neuroscientific pipelines in via the cloud-based computational reproducibility platform Code Ocean.
Difficulty level: Beginner
Duration: 17:01
Speaker: : David Feng

This lesson provides an overview of how to construct computational pipelines for neurophysiological data using DataJoint.
Difficulty level: Beginner
Duration: 17:37
Speaker: : Dimitri Yatsenko

This talk describes approaches to maintaining integrated workflows and data management schema, taking advantage of the many open source, collaborative platforms already existing.
Difficulty level: Beginner
Duration: 15:15
Speaker: : Erik C. Johnson

This hands-on tutorial walks you through DataJoint platform, highlighting features and schema which can be used to build robost neuroscientific pipelines.
Difficulty level: Beginner
Duration: 26:06
Speaker: : Milagros Marin

This lecture provides a detailed description of how to incorporate HED annotation into your neuroimaging data pipeline.
Difficulty level: Beginner
Duration: 33:36
Speaker: : Dung Truong

This talk covers the differences between applying HED annotation to fMRI datasets versus other neuroimaging practices, and also introduces an analysis pipeline using HED tags.
Difficulty level: Beginner
Duration: 22:52
Speaker: : Monique Denissen

This lesson provides a thorough description of neuroimaging development over time, both conceptually and technologically. You will learn about the fundamentals of imaging techniques such as MRI and PET, as well as how the resultant data may be used to generate novel data visualization schemas.
Difficulty level: Beginner
Duration: 1:43:57
Speaker: : Jack Van Horn

This lesson aims to define computational neuroscience in general terms, while providing specific examples of highly successful computational neuroscience projects.
Difficulty level: Beginner
Duration: 59:21
Speaker: : Alla Borisyuk

This lecture covers a wide range of aspects regarding neuroinformatics and data governance, describing both their historical developments and current trajectories. Particular tools, platforms, and standards to make your research more FAIR are also discussed.
Difficulty level: Beginner
Duration: 54:58
Speaker: : Franco Pestilli
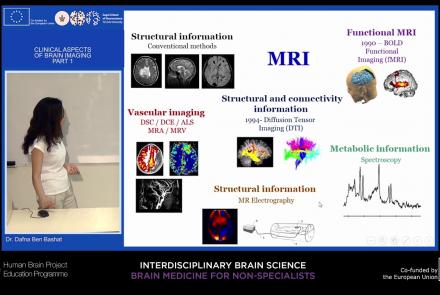
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

This lecture covers an Introduction to neuron anatomy and signaling, and different types of models, including the Hodgkin-Huxley model.
Difficulty level: Beginner
Duration: 1:23:01
Speaker: : Gaute Einevoll
Course:
This lesson gives an introduction to simple spiking neuron models.
Difficulty level: Beginner
Duration: 48 Slides
Speaker: : Zubin Bhuyan

Course:
This lecture focuses on where and how Jupyter notebooks can be used most effectively for education.
Difficulty level: Beginner
Duration: 34:53
Speaker: : Thomas Kluyver

Course:
JupyterHub is a simple, highly extensible, multi-user system for managing per-user Jupyter Notebook servers, designed for research groups or classes. This lecture covers deploying JupyterHub on a single server, as well as deploying with Docker using GitHub for authentication.
Difficulty level: Beginner
Duration: 1:36:27
Speaker: : Thomas Kluyver

Course:
In this tutorial, you will learn the basic features of uploading and versioning your data within OpenNeuro.org.
Difficulty level: Beginner
Duration: 5:36
Speaker: : OpenNeuro

Course:
This tutorial shows how to share your data in OpenNeuro.org.
Difficulty level: Beginner
Duration: 1:22
Speaker: : OpenNeuro

Course:
Following the previous two tutorials on uploading and sharing data with OpenNeuro.org, this tutorial briefly covers how to run various analyses on your datasets.
Difficulty level: Beginner
Duration: 2:26
Speaker: : OpenNeuro
This lesson provides an introduction to simple spiking neuron models.
Difficulty level: Beginner
Duration: 48 Slides
Speaker: : Zubin Bhuyan
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

The Virtual Brain (TVB) is an open-source, multi-scale, multi-modal brain simulation platform. In this lesson, you get introduced to brain simulation in general and to TVB in particular. This lesson also presents the newest approaches for clinical applications of TVB - that is, for stroke, epilepsy, brain tumors, and Alzheimer’s disease - and show how brain simulation can improve diagnostics, therapy, and understanding of neurological disease.
Difficulty level: Beginner
Duration: 1:35:08
Speaker: : Petra Ritter