Lesson type
Difficulty level

This lecture provides an introduction to the application of genetic testing in neurodevelopmental disorders.
Difficulty level: Beginner
Duration: 37:47
Speaker: : Diana-Laura Miclea

This lesson describes the fundamentals of genomics, from central dogma to design and implementation of GWAS, to the computation, analysis, and interpretation of polygenic risk scores.
Difficulty level: Intermediate
Duration: 1:28:16
Speaker: : Dan Felsky

This is a hands-on tutorial on PLINK, the open source whole genome association analysis toolset. The aims of this tutorial are to teach users how to perform basic quality control on genetic datasets, as well as to identify and understand GWAS summary statistics.
Difficulty level: Intermediate
Duration: 1:27:18
Speaker: : Dan Felsky

This is a tutorial on using the open-source software PRSice to calculate a set of polygenic risk scores (PRS) for a study sample. Users will also learn how to read PRS into R, visualize distributions, and perform basic association analyses.
Difficulty level: Intermediate
Duration: 1:53:34
Speaker: : Dan Felsky

This lesson is an overview of transcriptomics, from fundamental concepts of the central dogma and RNA sequencing at the single-cell level, to how genetic expression underlies diversity in cell phenotypes.
Difficulty level: Intermediate
Duration: 1:29:08
Speaker: : Shreejoy Tripathy

This is a tutorial introducing participants to the basics of RNA-sequencing data and how to analyze its features using Seurat.
Difficulty level: Intermediate
Duration: 1:19:17
Speaker: : Sonny Chen

Similarity Network Fusion (SNF) is a computational method for data integration across various kinds of measurements, aimed at taking advantage of the common as well as complementary information in different data types. This workshop walks participants through running SNF on EEG and genomic data using RStudio.
Difficulty level: Intermediate
Duration: 1:21:38
Speaker: : Dan Felsky

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This lecture provides an overview of successful open-access projects aimed at describing complex neuroscientific models, and makes a case for expanded use of resources in support of reproducibility and validation of models against experimental data.
Difficulty level: Beginner
Duration: 1:00:39
Speaker: : Sharon Crook

Course:
This lesson provides an overview of Jupyter notebooks, Jupyter lab, and Binder, as well as their applications within the field of neuroimaging, particularly when it comes to the writing phase of your research.
Difficulty level: Intermediate
Duration: 50:28
Speaker: : Elizabeth DuPre

Course:
The lecture provides an overview of the core skills and practical solutions required to practice reproducible research.
Difficulty level: Beginner
Duration: 1:25:17
Speaker: : Fernando Perez

Course:
This lecture covers the biomedical researcher's perspective on FAIR data sharing and the importance of finding better ways to manage large datasets.
Difficulty level: Beginner
Duration: 10:51
Speaker: : Adam Ferguson
Course:
This lecture covers multiple aspects of FAIR neuroscience data: what makes it unique, the challenges to making it FAIR, the importance of overcoming these challenges, and how data governance comes into play.
Difficulty level: Beginner
Duration: 14:56
Speaker: : Damian Eke

This lecture covers the processes, benefits, and challenges involved in designing, collecting, and sharing FAIR neuroscience datasets.
Difficulty level: Beginner
Duration: 11:35
Speaker: : Julie Boyle & Valentina Borghesani
This lecture covers the benefits and difficulties involved when re-using open datasets, and how metadata is important to the process.
Difficulty level: Beginner
Duration: 11:20
Speaker: : Elizabeth DuPre

Course:
This lecture will provide an overview of Addgene, a tool that embraces the FAIR principles developed by members of the INCF Community. This will include an overview of Addgene, their mission, and available resources.
Difficulty level: Beginner
Duration: 12:05
Speaker: : Joanne Kamens

This lecture covers the IBI Data Standards and Sharing Working Group, including its history, aims, and projects.
Difficulty level: Beginner
Duration: 3:58
Speaker: : Kenji Doya
This session covers the framework of the International Brain Lab (IBL) and the data architecture used for this project.
Difficulty level: Beginner
Duration: 23:37
Speaker: : Kenneth Harris
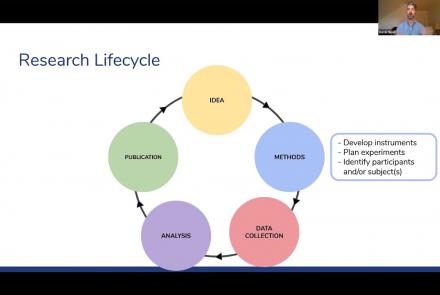
The Open Science Framework (OSF) provides avenues for researchers to design a study, as well as collect, analyze, and store data, manage collaborators, and publish research materials. In this webinar, attendees will learn about the many features of the OSF and develop strategies for using the tool within the context of their own research projects. The discussion will be framed around how to best utilize the OSF while also implementing data management and open science best practices.
Difficulty level: Beginner
Duration: 1:09:33
Speaker: : Kevin Read