Lesson type
Difficulty level

This lesson describes spike timing-dependent plasticity (STDP), a biological process that adjusts the strength of connections between neurons in the brain, and how one can implement or mimic this process in a computational model. You will also find links for practical exercises at the bottom of this page.
Difficulty level: Intermediate
Duration: 12:50
Speaker: : Dan Goodman

This lesson provides a brief introduction to the Computational Modeling of Neuronal Plasticity.
Difficulty level: Intermediate
Duration: 0:40
Speaker: : Florence I. Kleberg

In this lesson, you will be introducted to a type of neuronal model known as the leaky integrate-and-fire (LIF) model.
Difficulty level: Intermediate
Duration: 1:23
Speaker: : Florence I. Kleberg

This lesson goes over various potential inputs to neuronal synapses, loci of neural communication.
Difficulty level: Intermediate
Duration: 1:20
Speaker: : Florence I. Kleberg

This lesson describes the how and why behind implementing integration time steps as part of a neuronal model.
Difficulty level: Intermediate
Duration: 1:08
Speaker: : Florence I. Kleberg
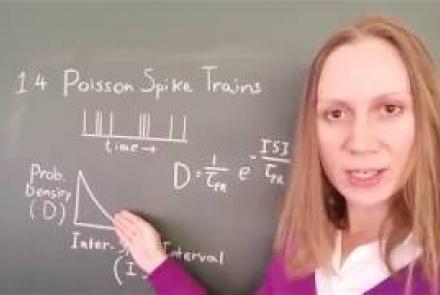
In this lesson, you will learn about neural spike trains which can be characterized as having a Poisson distribution.
Difficulty level: Intermediate
Duration: 1:18
Speaker: : Florence I. Kleberg

This lesson covers spike-rate adaptation, the process by which a neuron's firing pattern decays to a low, steady-state frequency during the sustained encoding of a stimulus.
Difficulty level: Intermediate
Duration: 1:26
Speaker: : Florence I. Kleberg

This lesson provides a brief explanation of how to implement a neuron's refractory period in a computational model.
Difficulty level: Intermediate
Duration: 0:42
Speaker: : Florence I. Kleberg

In this lesson, you will learn a computational description of the process which tunes neuronal connectivity strength, spike-timing-dependent plasticity (STDP).
Difficulty level: Intermediate
Duration: 2:40
Speaker: : Florence I. Kleberg

This lesson reviews theoretical and mathematical descriptions of correlated spike trains.
Difficulty level: Intermediate
Duration: 2:54
Speaker: : Florence I. Kleberg

This lesson investigates the effect of correlated spike trains on spike-timing dependent plasticity (STDP).
Difficulty level: Intermediate
Duration: 1:43
Speaker: : Florence I. Kleberg

This lesson goes over synaptic normalisation, the homeostatic process by which groups of weighted inputs scale up or down their biases.
Difficulty level: Intermediate
Duration: 2:58
Speaker: : Florence I. Kleberg

In this lesson, you will learn about the intrinsic plasticity of single neurons.
Difficulty level: Intermediate
Duration: 2:08
Speaker: : Florence I. Kleberg

This lesson covers short-term facilitation, a process whereby a neuron's synaptic transmission is enhanced for a short (sub-second) period.
Difficulty level: Intermediate
Duration: 1:58
Speaker: : Florence I. Kleberg

This lesson describes short-term depression, a reduction of synaptic information transfer between neurons.
Difficulty level: Intermediate
Duration: 1:40
Speaker: : Florence I. Kleberg

This lesson briefly wraps up the course on Computational Modeling of Neuronal Plasticity.
Difficulty level: Intermediate
Duration: 0:37
Speaker: : Florence I. Kleberg

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This talk goes over Neurobagel, an open-source platform developed for improved dataset sharing and searching.
Difficulty level: Beginner
Duration: 13:37
Speaker: : Jean-Babtiste Poline

In this lesson, you will learn about the BRAIN Initiative Cell Atlas Network (BICAN) and how this project adopts a federated approach to data sharing.
Difficulty level: Beginner
Duration: 11:23
Speaker: : Owen White

In this second part of the lecture Data Science and Reproducibility, you will learn how to apply the awareness of the intersection between neuroscience and data science (discussed in part one) to an understanding of the current reproducibility crisis in biomedical science and neuroscience.
Difficulty level: Beginner
Duration: 31:31
Speaker: : Ashley Juavinett