Lesson type
Difficulty level

This lecture provides an overview of successful open-access projects aimed at describing complex neuroscientific models, and makes a case for expanded use of resources in support of reproducibility and validation of models against experimental data.
Difficulty level: Beginner
Duration: 1:00:39
Speaker: : Sharon Crook

Course:
This talk deals with Identifiers.org, a central infrastructure for findable, accessible, interoperable and re-usable (FAIR) data, which provides a range of services to promote the citability of individual data providers and integration with e-infrastructures.
Difficulty level: Beginner
Duration: 36:41
Speaker: : Sarala Wimalaratne

Course:
This lecture provides an overview of the technology and demonstration of how Hypothes.is is being used within biomedicine.
Difficulty level: Beginner
Duration: 52:06
Speaker: : Maryann Martone

This tutorial covers the fundamentals of collaborating with Git and GitHub.
Difficulty level: Intermediate
Duration: 2:15:50
Speaker: : Elizabeth DuPre

Course:
This lesson provides an overview of Jupyter notebooks, Jupyter lab, and Binder, as well as their applications within the field of neuroimaging, particularly when it comes to the writing phase of your research.
Difficulty level: Intermediate
Duration: 50:28
Speaker: : Elizabeth DuPre

Course:
The lecture provides an overview of the core skills and practical solutions required to practice reproducible research.
Difficulty level: Beginner
Duration: 1:25:17
Speaker: : Fernando Perez

Course:
This lecture covers the biomedical researcher's perspective on FAIR data sharing and the importance of finding better ways to manage large datasets.
Difficulty level: Beginner
Duration: 10:51
Speaker: : Adam Ferguson
Course:
This lecture covers multiple aspects of FAIR neuroscience data: what makes it unique, the challenges to making it FAIR, the importance of overcoming these challenges, and how data governance comes into play.
Difficulty level: Beginner
Duration: 14:56
Speaker: : Damian Eke

This lecture covers the processes, benefits, and challenges involved in designing, collecting, and sharing FAIR neuroscience datasets.
Difficulty level: Beginner
Duration: 11:35
Speaker: : Julie Boyle & Valentina Borghesani
This lecture covers the benefits and difficulties involved when re-using open datasets, and how metadata is important to the process.
Difficulty level: Beginner
Duration: 11:20
Speaker: : Elizabeth DuPre

Course:
This lecture will provide an overview of Addgene, a tool that embraces the FAIR principles developed by members of the INCF Community. This will include an overview of Addgene, their mission, and available resources.
Difficulty level: Beginner
Duration: 12:05
Speaker: : Joanne Kamens
Course:
This session will include presentations of infrastructure that embrace the FAIR principles developed by members of the INCF Community. This lecture provides an overview and demo of the Canadian Open Neuroscience Platform (CONP).
Difficulty level: Beginner
Duration: 14:02
Speaker: : Tristan Glatard & Samir Das

This lecture covers the IBI Data Standards and Sharing Working Group, including its history, aims, and projects.
Difficulty level: Beginner
Duration: 3:58
Speaker: : Kenji Doya
This session covers the framework of the International Brain Lab (IBL) and the data architecture used for this project.
Difficulty level: Beginner
Duration: 23:37
Speaker: : Kenneth Harris

This video gives a short introduction to the EBRAINS data sharing platform, why it was developed, and how it contributes to open data sharing.
Difficulty level: Beginner
Duration: 17:32
Speaker: : Ida Aasebø

This video introduces the key principles for data organization and explains how you could make your data FAIR for data sharing on EBRAINS.
Difficulty level: Beginner
Duration: 10:54
Speaker: : Maaike van Swieten

This video introduces the importance of writing a Data Descriptor to accompany your dataset on EBRAINS. It gives concrete examples on what information to include and highlights how this makes your data more FAIR.
Difficulty level: Beginner
Duration: 9:48
Speaker: : Ingrid Reiten

This video demonstrates how to find, access, and download data on EBRAINS.
Difficulty level: Beginner
Duration: 14:27
Speaker: : Maaike van Swieten
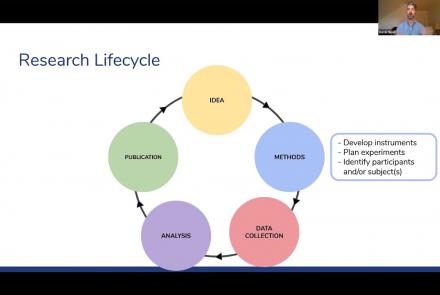
The Open Science Framework (OSF) provides avenues for researchers to design a study, as well as collect, analyze, and store data, manage collaborators, and publish research materials. In this webinar, attendees will learn about the many features of the OSF and develop strategies for using the tool within the context of their own research projects. The discussion will be framed around how to best utilize the OSF while also implementing data management and open science best practices.
Difficulty level: Beginner
Duration: 1:09:33
Speaker: : Kevin Read
The FOSTER portal has produced a number of guides to help implement Open Science practices in daily workflows, including The Open Science Training Handbook. It provides many basic definitions, concepts, and principles that are key components of open science, as well as general guidance for developing and implementing these practices in one's own research environments.
Difficulty level: Beginner
Duration:
Speaker: :