Lesson type
Difficulty level

Manipulate the default connectome provided with TVB to see how structural lesions effect brain dynamics. In this hands-on session you will insert lesions into the connectome within the TVB graphical user interface (GUI). Afterwards, the modified connectome will be used for simulations and the resulting activity will be analysed using functional connectivity.
Difficulty level: Beginner
Duration: 31:22
Speaker: : Paul Triebkorn

This presentation discusses the impact of data sharing in stroke.
Difficulty level: Intermediate
Duration: 16:33
Speaker: : Valeria Caso

This talks presents an overview of the potential for data federation in stroke research.
Difficulty level: Intermediate
Duration: 21:37
Speaker: : Maurizio A. Leone

Course:
This talk focuses on the EAN Scientific Panel of Stroke, in particular on the aims and roles of the panel.
Difficulty level: Intermediate
Duration: 18:19
Speaker: : Anna Bersano

This lightning talk describes an automated pipline for positron emission tomography (PET) data.
Difficulty level: Intermediate
Duration: 7:27
Speaker: : Soodeh Moallemian
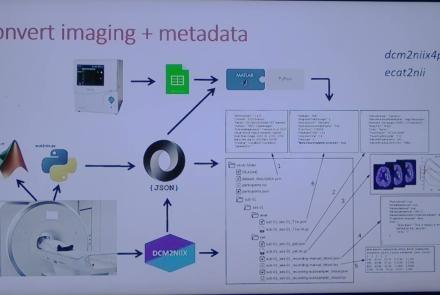
This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 9:23
Speaker: : Cyril Pernet

This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 41:04
Speaker: : Martin Nørgaard
This session dives into practical PET tooling on BIDS data—showing how to run motion correction, register PET↔MRI, extract time–activity curves, and generate standardized PET-BIDS derivatives with clear QC reports. It introduces modular BIDS Apps (head-motion correction, TAC extraction), a full pipeline (PETPrep), and a PET/MRI defacer, with guidance on parameters, outputs, provenance, and why Dockerized containers are the reliable way to run them at scale.
Difficulty level: Intermediate
Duration: 1:05:38
Speaker: : Martin Nørgaard

This session introduces two PET quantification tools—bloodstream for processing arterial blood data and kinfitr for kinetic modeling and quantification—built to work with BIDS/BIDS-derivatives and containers. Bloodstream fuses autosampler and manual measurements (whole blood, plasma, parent fraction) using interpolation or fitted models (incl. hierarchical GAMs) to produce a clean arterial input function (AIF) and whole-blood curves with rich QC reports ready. TAC data (e.g., from PETPrep) and blood (e.g., from bloodstream) can be ingested using kinfitr to run reproducible, GUI-driven analyses: define combined ROIs, calculate weighting factors, estimate blood–tissue delay, choose and chain models (e.g., 2TCM → 1TCM with parameter inheritance), and export parameters/diagnostics. Both are available as Docker apps; workflows emphasize configuration files, reports, and standard outputs to support transparency and reuse.
Difficulty level: Intermediate
Duration: 1:20:56
Speaker: : Granville Matheson

This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz

Course:
This module covers many of the types of non-invasive neurotech and neuroimaging devices including electroencephalography (EEG), electromyography (EMG), electroneurography (ENG), magnetoencephalography (MEG), and more.
Difficulty level: Beginner
Duration: 13:36
Speaker: : Harrison Canning

This short talk addresses how to use VisuAlign to make nonlinear adjustments to 2D-to-3D registrations generated by QuickNII.
Difficulty level: Beginner
Duration: 08:50
Speaker: : Maja Puchades

This talk aims to provide guidance regarding the myriad labelling methods for histological image data.
Difficulty level: Beginner
Duration: 35:20
Speaker: : Sharon Yates

This lesson provides a cross-species comparison of neuron types in the rat and mouse brain.
Difficulty level: Beginner
Duration: 17:16
Speaker: : Ingvild Elise Bjerke

This lecture concludes the course with an outline of future directions of the field of neuroscientific research data integration.
Difficulty level: Beginner
Duration: 09:49
Speaker: : Jan G. Bjaalie

This is a hands-on tutorial on PLINK, the open source whole genome association analysis toolset. The aims of this tutorial are to teach users how to perform basic quality control on genetic datasets, as well as to identify and understand GWAS summary statistics.
Difficulty level: Intermediate
Duration: 1:27:18
Speaker: : Dan Felsky

This lesson is an overview of transcriptomics, from fundamental concepts of the central dogma and RNA sequencing at the single-cell level, to how genetic expression underlies diversity in cell phenotypes.
Difficulty level: Intermediate
Duration: 1:29:08
Speaker: : Shreejoy Tripathy

In this lesson, you will learn about data management within the Open Data Commons (ODC) framework, and in particular, how Spinal Cord Injury (SCI) data is stored, shared, and published. You will also hear about Frictionless Data, an open-source toolkit aimed at simplifying the data experience.
Difficulty level: Beginner
Duration: 19:10
Speaker: : Jeff Grethe & Sourabh Prakash

This talk describes the NIH-funded SPARC Data Structure, and how this project navigates ontology development while keeping in mind the FAIR science principles.
Difficulty level: Beginner
Duration: 25:44
Speaker: : Fahim Imam

This talk goes over Neurobagel, an open-source platform developed for improved dataset sharing and searching.
Difficulty level: Beginner
Duration: 13:37
Speaker: : Jean-Babtiste Poline