Lesson type
Difficulty level

This lesson describes the fundamentals of genomics, from central dogma to design and implementation of GWAS, to the computation, analysis, and interpretation of polygenic risk scores.
Difficulty level: Intermediate
Duration: 1:28:16
Speaker: : Dan Felsky

Course:
This lesson provides an overview of the database of Genotypes and Phenotypes (dbGaP), which was developed to archive and distribute the data and results from studies that have investigated the interaction of genotype and phenotype in humans.
Difficulty level: Beginner
Duration: 48:22
Speaker: : Michael Feolo

This tutorial demonstrates how to perform cell-type deconvolution in order to estimate how proportions of cell-types in the brain change in response to various conditions. While these techniques may be useful in addressing a wide range of scientific questions, this tutorial will focus on the cellular changes associated with major depression (MDD).
Difficulty level: Intermediate
Duration: 1:15:14
Speaker: : Keon Arbabi

In this lesson, you will learn about data management within the Open Data Commons (ODC) framework, and in particular, how Spinal Cord Injury (SCI) data is stored, shared, and published. You will also hear about Frictionless Data, an open-source toolkit aimed at simplifying the data experience.
Difficulty level: Beginner
Duration: 19:10
Speaker: : Jeff Grethe & Sourabh Prakash

This lesson introduces several open science tools like Docker and Apptainer which can be used to develop portable and reproducible software environments.
Difficulty level: Beginner
Duration: 17:22
Speaker: : Joanes Grandjean

This talk covers the differences between applying HED annotation to fMRI datasets versus other neuroimaging practices, and also introduces an analysis pipeline using HED tags.
Difficulty level: Beginner
Duration: 22:52
Speaker: : Monique Denissen

Course:
This lesson provides a brief visual walkthrough on the necessary steps when copying data from one brainlife project to another.
Difficulty level: Beginner
Duration: 1:07
Speaker: :

Course:
This lesson visually documents the process of uploading data to brainlife via the command line interface (CLI).
Difficulty level: Beginner
Duration: 1:28
Speaker: :

Course:
This video shows how to use the brainlife.io interface to edit the participants' info file. This file is the ParticipantInfo.json file of the Brain Imaging Data Structure (BIDS).
Difficulty level: Beginner
Duration: 0:34
Speaker: :

Course:
This video will document the process of running an app on brainlife, from data staging to archiving of the final data outputs.
Difficulty level: Beginner
Duration: 3:43
Speaker: :

Course:
This video demonstrates each required step for preprocessing T1w anatomical data in brainlife.io.
Difficulty level: Beginner
Duration: 3:28
Speaker: :

Course:
This short video shows how data in a brainlife.io publication can be opened from a DOI inside a published article. The video provides an example of how the DOI deposited on the journal can be opened with a web browser to redirect to the associated data publication on brainlife.io.
Difficulty level: Beginner
Duration: 2:18
Speaker: :

This lecture contains an overview of electrophysiology data reuse within the EBRAINS ecosystem.
Difficulty level: Beginner
Duration: 15:57
Speaker: : Andrew Davison

This video explains what metadata is, why it is important, and how you can organize your metadata to increase the FAIRness of your data on EBRAINS.
Difficulty level: Beginner
Duration: 17:23
Speaker: : Ulrike Schlegel

Course:
This lecture covers the rationale for developing the DAQCORD, a framework for the design, documentation, and reporting of data curation methods in order to advance the scientific rigour, reproducibility, and analysis of data.
Difficulty level: Intermediate
Duration: 17:08
Speaker: : Ari Ercole

In this session the Medical Informatics Platform (MIP) federated analytics is presented. The current and future analytical tools implemented in the MIP will be detailed along with the constructs, tools, processes, and restrictions that formulate the solution provided. MIP is a platform providing advanced federated analytics for diagnosis and research in clinical neuroscience research. It is targeting clinicians, clinical scientists and clinical data scientists. It is designed to help adopt advanced analytics, explore harmonized medical data of neuroimaging, neurophysiological and medical records as well as research cohort datasets, without transferring original clinical data. It can be perceived as a virtual database that seamlessly presents aggregated data from distributed sources, provides access and analyze imaging and clinical data, securely stored in hospitals, research archives and public databases. It leverages and re-uses decentralized patient data and research cohort datasets, without transferring original data. Integrated statistical analysis tools and machine learning algorithms are exposed over harmonized, federated medical data.
Difficulty level: Intermediate
Duration: 15:05
Speaker: : Giorgos Papanikos

The Medical Informatics Platform (MIP) is a platform providing federated analytics for diagnosis and research in clinical neuroscience research. The federated analytics is possible thanks to a distributed engine that executes computations and transfers information between the members of the federation (hospital nodes). In this talk the speaker will describe the process of designing and implementing new analytical tools, i.e. statistical and machine learning algorithms. Mr. Sakellariou will further describe the environment in which these federated algorithms run, the challenges and the available tools, the principles that guide its design and the followed general methodology for each new algorithm. One of the most important challenges which are faced is to design these tools in a way that does not compromise the privacy of the clinical data involved. The speaker will show how to address the main questions when designing such algorithms: how to decompose and distribute the computations and what kind of information to exchange between nodes, in order to comply with the privacy constraint mentioned above. Finally, also the subject of validating these federated algorithms will be briefly touched.
Difficulty level: Intermediate
Duration: 20:26
Speaker: : Jason Skellariou

The Medical Informatics Platform (MIP) Dementia had been installed in several memory clinics across Europe allowing them to federate their real-world databases. Research open access databases had also been integrated such as ADNI (Alzheimer’s Dementia Neuroimaging Initiative), reaching a cumulative case load of more than 5,000 patients (major cognitive disorder due to Alzheimer’s disease, other major cognitive disorder, minor cognitive disorder, controls). The statistic and machine learning tools implemented in the MIP allowed researchers to conduct easily federated analyses among Italian memory clinics (Redolfi et al. 2020) and also across borders between the French (Lille), the Swiss (Lausanne) and the Italian (Brescia) datasets.
Difficulty level: Intermediate
Duration: 16:44
Speaker: : Mélanie Leroy
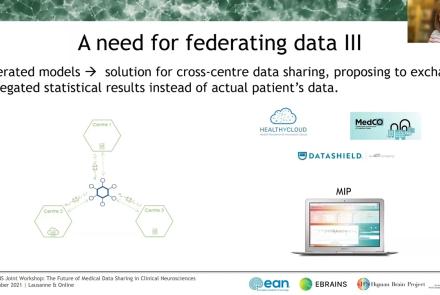
This talks presents ethics requirements of the Medical Informatics Platform, a data sharing platform for medical data using data federation mechanisms. The talk presents how the Medical Informatics Platform (MIP) works and which ethical requirements need to be considered when working with federated data.
Difficulty level: Intermediate
Duration: 16:25
Speaker: : Erika Borcel

This lecture talks about the usage of knowledge graphs in hospitals and related challenges of semantic interoperability.
Difficulty level: Intermediate
Duration: 24:32
Speaker: : Cristophe Gaudet-Blavignac