Lesson type
Difficulty level

Course:
This talk introduces Bayes' theorem, which describes the probability of an event, based on prior knowledge of conditions that might be related to the event.
Difficulty level: Beginner
Duration: 7:57
Speaker: : Barton Poulson

Course:
This lesson recaps why math, in a number of ways, is extremely useful in data science.
Difficulty level: Beginner
Duration: 1:35
Speaker: : Barton Poulson

Course:
This lesson provides an introduction to the lessons in this course that deal with statistics and why they are useful for data science.
Difficulty level: Beginner
Duration: 4:01
Speaker: : Barton Poulson

Course:
In this lesson, users will learn about the importance of exploratory analysis, as well as how statistics enables one to become familiar with and understand one's data.
Difficulty level: Beginner
Duration: 2:23
Speaker: : Barton Poulson

Course:
This lesson goes over graphical data exploration, including motivations for its use as well as practical examples of visualizing data distributions.
Difficulty level: Beginner
Duration: 8:01
Speaker: : Barton Poulson

Course:
In this lesson, users learn about exploratory statistics, and are introduced to various methods for numerical data exploration.
Difficulty level: Beginner
Duration: 5:05
Speaker: : Barton Poulson

Course:
This lesson overview some simple descriptions of statistical data.
Difficulty level: Beginner
Duration: 10:16
Speaker: : Barton Poulson

Course:
This lesson covers the basics of hypothesis testing.
Difficulty level: Beginner
Duration: 6:04
Speaker: : Barton Poulson

In this lecture, the speaker demonstrates Neurokernel's module interfacing feature by using it to integrate independently developed models of olfactory and vision LPUs based upon experimentally obtained connectivity information.
Difficulty level: Intermediate
Duration: 29:56
Speaker: : Aurel A. Lazar

Course:
This lesson describes the Neuroscience Gateway , which facilitates access and use of National Science Foundation High Performance Computing resources by neuroscientists.
Difficulty level: Beginner
Duration: 39:27
Speaker: : Subha Sivagnanam

Course:
This lesson gives an introduction to high-performance computing with the Compute Canada network, first providing an overview of use cases for HPC and then a hands-on tutorial. Though some examples might seem specific to the Calcul Québec, all computing clusters in the Compute Canada network share the same software modules and environments.
Difficulty level: Beginner
Duration: 02:49:34
Speaker: : Félix-Antoine Fortin

This lesson provides a short overview of the main features of the Canadian Open Neuroscience Platform (CONP) Portal, a web interface that facilitates open science for the neuroscience community by simplifying global access to and sharing of datasets and tools. The Portal internalizes the typical cycle of a research project, beginning with data acquisition, followed by data processing with published tools, and ultimately the publication of results with a link to the original dataset.
Difficulty level: Beginner
Duration: 14:03
Speaker: : Samir Das, Tristan Glatard

Course:
This talk presents an overview of CBRAIN, a web-based platform that allows neuroscientists to perform computationally intensive data analyses by connecting them to high-performance computing facilities across Canada and around the world.
Difficulty level: Beginner
Duration: 56:07
Speaker: : Shawn Brown

In this talk the speakers will give a brief introduction of the Fenix Infrastructure and Service Offering, before focusing on Data Safety. The speaker will take the participants through the ETHZ-CSCS offering for EBRAINS and all the HBP Communities highlighting the Infrastructure role in a service implementation in respect of Security. Particular attention will be on showing what tools ETHZ-CSCS provides to a Portal/Service provider such as EBRAINS, MIP/HIP, TVB, NRP amongst others. Finally there will be given a quick glimpse into the future and the role that “multi-tenancy” will play.
Difficulty level: Intermediate
Duration: 20:05
Speaker: : Alex Upton and Stefano Gorini
Course:
This book was written with the goal of introducing researchers and students in a variety of research fields to the intersection of data science and neuroimaging. This book reflects our own experience of doing research at the intersection of data science and neuroimaging and it is based on our experience working with students and collaborators who come from a variety of backgrounds and have a variety of reasons for wanting to use data science approaches in their work. The tools and ideas that we chose to write about are all tools and ideas that we have used in some way in our own research. Many of them are tools that we use on a daily basis in our work. This was important to us for a few reasons: the first is that we want to teach people things that we ourselves find useful. Second, it allowed us to write the book with a focus on solving specific analysis tasks. For example, in many of the chapters you will see that we walk you through ideas while implementing them in code, and with data. We believe that this is a good way to learn about data analysis, because it provides a connecting thread from scientific questions through the data and its representation to implementing specific answers to these questions. Finally, we find these ideas compelling and fruitful. That’s why we were drawn to them in the first place. We hope that our enthusiasm about the ideas and tools described in this book will be infectious enough to convince the readers of their value.
Difficulty level: Intermediate
Duration:
Speaker: :

In this session the Medical Informatics Platform (MIP) federated analytics is presented. The current and future analytical tools implemented in the MIP will be detailed along with the constructs, tools, processes, and restrictions that formulate the solution provided. MIP is a platform providing advanced federated analytics for diagnosis and research in clinical neuroscience research. It is targeting clinicians, clinical scientists and clinical data scientists. It is designed to help adopt advanced analytics, explore harmonized medical data of neuroimaging, neurophysiological and medical records as well as research cohort datasets, without transferring original clinical data. It can be perceived as a virtual database that seamlessly presents aggregated data from distributed sources, provides access and analyze imaging and clinical data, securely stored in hospitals, research archives and public databases. It leverages and re-uses decentralized patient data and research cohort datasets, without transferring original data. Integrated statistical analysis tools and machine learning algorithms are exposed over harmonized, federated medical data.
Difficulty level: Intermediate
Duration: 15:05
Speaker: : Giorgos Papanikos

The Medical Informatics Platform (MIP) is a platform providing federated analytics for diagnosis and research in clinical neuroscience research. The federated analytics is possible thanks to a distributed engine that executes computations and transfers information between the members of the federation (hospital nodes). In this talk the speaker will describe the process of designing and implementing new analytical tools, i.e. statistical and machine learning algorithms. Mr. Sakellariou will further describe the environment in which these federated algorithms run, the challenges and the available tools, the principles that guide its design and the followed general methodology for each new algorithm. One of the most important challenges which are faced is to design these tools in a way that does not compromise the privacy of the clinical data involved. The speaker will show how to address the main questions when designing such algorithms: how to decompose and distribute the computations and what kind of information to exchange between nodes, in order to comply with the privacy constraint mentioned above. Finally, also the subject of validating these federated algorithms will be briefly touched.
Difficulty level: Intermediate
Duration: 20:26
Speaker: : Jason Skellariou

The Medical Informatics Platform (MIP) Dementia had been installed in several memory clinics across Europe allowing them to federate their real-world databases. Research open access databases had also been integrated such as ADNI (Alzheimer’s Dementia Neuroimaging Initiative), reaching a cumulative case load of more than 5,000 patients (major cognitive disorder due to Alzheimer’s disease, other major cognitive disorder, minor cognitive disorder, controls). The statistic and machine learning tools implemented in the MIP allowed researchers to conduct easily federated analyses among Italian memory clinics (Redolfi et al. 2020) and also across borders between the French (Lille), the Swiss (Lausanne) and the Italian (Brescia) datasets.
Difficulty level: Intermediate
Duration: 16:44
Speaker: : Mélanie Leroy
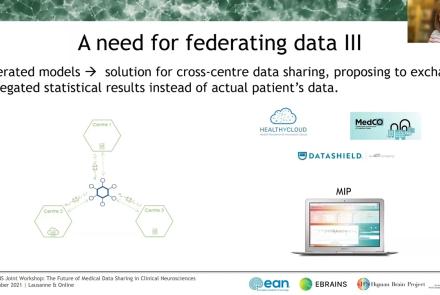
This talks presents ethics requirements of the Medical Informatics Platform, a data sharing platform for medical data using data federation mechanisms. The talk presents how the Medical Informatics Platform (MIP) works and which ethical requirements need to be considered when working with federated data.
Difficulty level: Intermediate
Duration: 16:25
Speaker: : Erika Borcel

This lecture talks about the usage of knowledge graphs in hospitals and related challenges of semantic interoperability.
Difficulty level: Intermediate
Duration: 24:32
Speaker: : Cristophe Gaudet-Blavignac