Lesson type
Difficulty level
Course:
This lesson discusses FAIR principles and methods currently in development for assessing FAIRness.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

This lecture provides an overview of successful open-access projects aimed at describing complex neuroscientific models, and makes a case for expanded use of resources in support of reproducibility and validation of models against experimental data.
Difficulty level: Beginner
Duration: 1:00:39
Speaker: : Sharon Crook

This lecture provides an introduction to the Brain Imaging Data Structure (BIDS), a standard for organizing human neuroimaging datasets.
Difficulty level: Intermediate
Duration: 56:49
Speaker: : Chris Gorgolewski

This lesson provides an overview of Neurodata Without Borders (NWB), an ecosystem for neurophysiology data standardization. The lecture also introduces some NWB-enabled tools.
Difficulty level: Beginner
Duration: 29:53
Speaker: : Oliver Ruebel
Course:
This lesson outlines Neurodata Without Borders (NWB), a data standard for neurophysiology which provides neuroscientists with a common standard to share, archive, use, and build analysis tools for neurophysiology data.
Difficulty level: Intermediate
Duration: 29:53
Speaker: : Oliver Ruebel

Course:
This lecture covers the rationale for developing the DAQCORD, a framework for the design, documentation, and reporting of data curation methods in order to advance the scientific rigour, reproducibility, and analysis of data.
Difficulty level: Intermediate
Duration: 17:08
Speaker: : Ari Ercole

Course:
This tutorial demonstrates how to use PyNN, a simulator-independent language for building neuronal network models, in conjunction with the neuromorphic hardware system SpiNNaker.
Difficulty level: Intermediate
Duration: 25:49
Speaker: : Christian Brenninkmeijer

Course:
This is an introductory lecture on whole-brain modelling, delving into the various spatial scales of neuroscience, neural population models, and whole-brain modelling. Additionally, the clinical applications of building and testing such models are characterized.
Difficulty level: Intermediate
Duration: 1:24:44
Speaker: : John Griffiths

Course:
This lecture covers FAIR atlases, including their background and construction, as well as how they can be created in line with the FAIR principles.
Difficulty level: Beginner
Duration: 14:24
Speaker: : Heidi Kleven

This lesson discusses the need for and approaches to integrating data across the various temporal and spatial scales in which brain activity can be measured.
Difficulty level: Beginner
Duration: 1:35:37
Speaker: : Leon Martin & Leon Stefnovski

This lesson consists of lecture and tutorial components, focusing on resources and tools which facilitate multi-scale brain modeling and simulation.
Difficulty level: Beginner
Duration: 3:46:21
Speaker: : Dionysios Perdikis

In this talk, challenges of handling complex neuroscientific data are discussed, as well as tools and services for the annotation, organization, storage, and sharing of these data.
Difficulty level: Beginner
Duration: 21:49
Speaker: : Thomas Wachtler

This lecture describes the neuroscience data respository G-Node Infrastructure (GIN), which provides platform independent data access and enables easy data publishing.
Difficulty level: Beginner
Duration: 22:23
Speaker: : Michael Sonntag

Course:
Overview of the content for Day 1 of this course.
Difficulty level: Beginner
Duration: 00:01:59
Speaker: : Tristan Shuman

Course:
Best practices: the tips and tricks on how to get your Miniscope to work and how to get your experiments off the ground.
Difficulty level: Beginner
Duration: 00:53:34
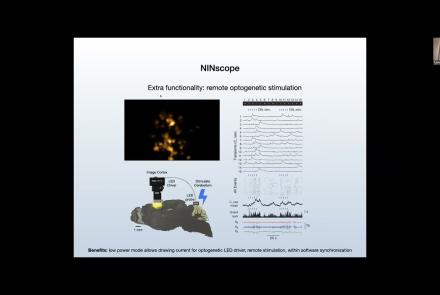
Course:
This talk delves into challenges and opportunities of Miniscope design, seeking the optimal balance between scale and function.
Difficulty level: Beginner
Duration: 00:21:51
Speaker: : Susie Feng, Zach Pennington, Tycho Hoogland

Course:
Attendees of this talk will learn aobut computational imaging systems and associated pipelines, as well as open-source software solutions supporting miniscope use.
Difficulty level: Beginner
Duration: 00:17:56
Speaker: : Susie Feng, Zach Pennington, Laura Waller

Course:
This talk covers the present state and future directions of calcium imaging data analysis, particularly in the context of one-photon vs two-photon approaches.
Difficulty level: Beginner
Duration: 00:21:06

Course:
In this talk, results from rodent experimentation using in vivo imaging are presented, demonstrating how the monitoring of neural ensembles may reveal patterns of learning during spatial tasks.
Difficulty level: Beginner
Duration: 00:19:43
Speaker: : Susie Feng, Zach Pennington, William Mau

Course:
How to start processing the raw imaging data generated with a Miniscope, including developing a usable pipeline and demoing the Minion pipeline.
Difficulty level: Beginner
Duration: 00:57:26
Speaker: : Daniel Aharoni, Phil Dong