Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This lecture discusses what defines an integrative approach regarding research and methods, including various study designs and models which are appropriate choices when attempting to bridge data domains; a necessity when whole-person modelling.
Difficulty level: Beginner
Duration: 1:28:14
Speaker: : Dan Felsky

This lecture covers the three big questions: What is the universe?, what is life?, and what is consciousness?
Difficulty level: Beginner
Duration: 1:07:52
Speaker: : Paul F.M.J. Verschure

This lecture outlines various approaches to studying Mind, Brain, and Behavior.
Difficulty level: Beginner
Duration: 1:02:34
Speaker: : Paul F.M.J. Verschure

This lecture covers the history of behaviorism and the ultimate challenge to behaviorism.
Difficulty level: Beginner
Duration: 1:19:08
Speaker: : Paul F.M.J. Verschure

This lecture covers various learning theories.
Difficulty level: Beginner
Duration: 1:00:42
Speaker: : Paul F.M.J. Verschure
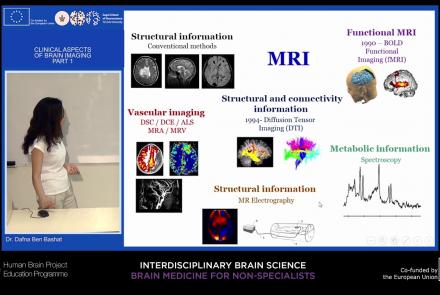
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

In this lesson, you will learn about how genetics can contribute to our understanding of psychiatric phenotypes.
Difficulty level: Beginner
Duration: 55:15
Speaker: : Sven Cichon
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

Course:
This lecture covers FAIR atlases, including their background and construction, as well as how they can be created in line with the FAIR principles.
Difficulty level: Beginner
Duration: 14:24
Speaker: : Heidi Kleven
Course:
This lecture covers the needs and challenges involved in creating a FAIR ecosystem for neuroimaging research.
Difficulty level: Beginner
Duration: 12:26
Speaker: : Camille Maumet

This lecture covers the NIDM data format within BIDS to make your datasets more searchable, and how to optimize your dataset searches.
Difficulty level: Beginner
Duration: 12:33
Speaker: : David Keator
This lecture covers the processes, benefits, and challenges involved in designing, collecting, and sharing FAIR neuroscience datasets.
Difficulty level: Beginner
Duration: 11:35
Speaker: : Julie Boyle & Valentina Borghesani
This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz
This lecture covers the benefits and difficulties involved when re-using open datasets, and how metadata is important to the process.
Difficulty level: Beginner
Duration: 11:20
Speaker: : Elizabeth DuPre
This lecture provides guidance on the ethical considerations the clinical neuroimaging community faces when applying the FAIR principles to their research.
Difficulty level: Beginner
Duration: 13:11
Speaker: : Gustav Nilsonne

Course:
This lesson gives an introduction to high-performance computing with the Compute Canada network, first providing an overview of use cases for HPC and then a hands-on tutorial. Though some examples might seem specific to the Calcul Québec, all computing clusters in the Compute Canada network share the same software modules and environments.
Difficulty level: Beginner
Duration: 02:49:34
Speaker: : Félix-Antoine Fortin