Lesson type
Difficulty level

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This lesson gives a description of the BrainHealth Databank, a repository of many types of health-related data, whose aim is to accelerate research, improve care, and to help better understand and diagnose mental illness, as well as develop new treatments and prevention strategies.
This lesson corresponds to slides 46-78 of the PDF below.
Difficulty level: Beginner
Duration: 1:12:25
Speaker: : Joanna Yu

This lecture covers different perspectives on the study of the mental, focusing on the difference between Mind and Brain.
Difficulty level: Beginner
Duration: 1:16:30
Speaker: : Paul F.M.J. Verschure
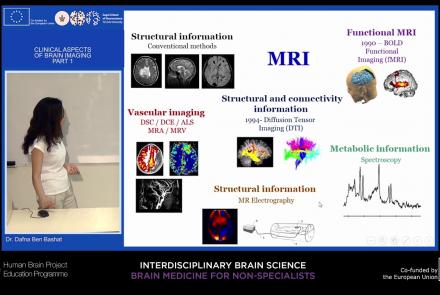
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

In this lesson, you will learn about how genetics can contribute to our understanding of psychiatric phenotypes.
Difficulty level: Beginner
Duration: 55:15
Speaker: : Sven Cichon

This lecture gives an introduction to the types of glial cells, homeostasis (influence of cerebral blood flow and influence on neurons), insulation and protection of axons (myelin sheath; nodes of Ranvier), microglia and reactions of the CNS to injury.
Difficulty level: Beginner
Duration: 40:32
Speaker: : Christine Bandtlow

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

Course:
This lecture presents an overview of functional brain parcellations, as well as a set of tutorials on bootstrap agregation of stable clusters (BASC) for fMRI brain parcellation.
Difficulty level: Advanced
Duration: 50:28
Speaker: : Pierre Bellec

Course:
The lecture provides an overview of the core skills and practical solutions required to practice reproducible research.
Difficulty level: Beginner
Duration: 1:25:17
Speaker: : Fernando Perez

Course:
This lecture covers the biomedical researcher's perspective on FAIR data sharing and the importance of finding better ways to manage large datasets.
Difficulty level: Beginner
Duration: 10:51
Speaker: : Adam Ferguson
Course:
This lecture covers the needs and challenges involved in creating a FAIR ecosystem for neuroimaging research.
Difficulty level: Beginner
Duration: 12:26
Speaker: : Camille Maumet
Course:
This lecture covers multiple aspects of FAIR neuroscience data: what makes it unique, the challenges to making it FAIR, the importance of overcoming these challenges, and how data governance comes into play.
Difficulty level: Beginner
Duration: 14:56
Speaker: : Damian Eke

This lecture covers how to make modeling workflows FAIR by working through a practical example, dissecting the steps within the workflow, and detailing the tools and resources used at each step.
Difficulty level: Beginner
Duration: 15:14
Speaker: : Salvador Dura-Bernal
This lecture focuses on the structured validation process within computational neuroscience, including the tools, services, and methods involved in simulation and analysis.
Difficulty level: Beginner
Duration: 14:19
Speaker: : Michael Denker

This lecture covers the NIDM data format within BIDS to make your datasets more searchable, and how to optimize your dataset searches.
Difficulty level: Beginner
Duration: 12:33
Speaker: : David Keator
This lecture covers the processes, benefits, and challenges involved in designing, collecting, and sharing FAIR neuroscience datasets.
Difficulty level: Beginner
Duration: 11:35
Speaker: : Julie Boyle & Valentina Borghesani
This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz
This lecture covers the benefits and difficulties involved when re-using open datasets, and how metadata is important to the process.
Difficulty level: Beginner
Duration: 11:20
Speaker: : Elizabeth DuPre
This lecture provides guidance on the ethical considerations the clinical neuroimaging community faces when applying the FAIR principles to their research.
Difficulty level: Beginner
Duration: 13:11
Speaker: : Gustav Nilsonne

This lecture discusses the FAIR principles as they apply to electrophysiology data and metadata, the building blocks for community tools and standards, platforms and grassroots initiatives, and the challenges therein.
Difficulty level: Beginner
Duration: 8:11
Speaker: : Thomas Wachtler