Displaying 938 results

Course:
This lecture covers the concepts of the architecture and convolution of traditional convolutional neural networks, the characteristics of graph and graph convolution, and spectral graph convolutional neural networks and how to perform spectral convolution, as well as the complete spectrum of Graph Convolutional Networks (GCNs), starting with the implementation of Spectral Convolution through Spectral Networks. It then provides insights on applicability of the other convolutional definition of Template Matching to graphs, leading to Spatial networks. This lecture is a part of the Deep Learning Course at NYU's Center for Data Science. Prerequisites for this module include: Modules 1 - 5 of this course and an Introduction to Data Science or a Graduate Level Machine Learning course.
Difficulty level: Advanced
Duration: 2:00:22
Speaker: : Xavier Bresson

Course:
This tutuorial covers the concept of graph convolutional networks and is a part of the Deep Learning Course at NYU's Center for Data Science. Prerequisites for this module include: Modules 1 - 5 of this course and an Introduction to Data Science or a Graduate Level Machine Learning course.
Difficulty level: Advanced
Duration: 57:33
Speaker: : Alfredo Canziani

Course:
This lecture covers the concept of model predictive control and is a part of the Deep Learning Course at NYU's Center for Data Science. Prerequisites for this module include: Models 1-6 of this course and an Introduction to Data Science or a Graduate Level Machine Learning course.
Difficulty level: Advanced
Duration: 1:10:22
Speaker: : Alfredo Canziani

Course:
This lecture covers the concepts of emulation of kinematics from observations and training a policy. It is a part of the Deep Learning Course at NYU's Center for Data Science. Prerequisites for this module include: Models 1-6 of this course and an Introduction to Data Science or a Graduate Level Machine Learning course.
Difficulty level: Advanced
Duration: 1:01:21
Speaker: : Alfredo Canziani

Course:
This lecture covers the concept of predictive policy learning under uncertainty and is a part of the Deep Learning Course at NYU's Center for Data Science. Prerequisites for this module include: Models 1-6 of this course and an Introduction to Data Science or a Graduate Level Machine Learning course.
Difficulty level: Advanced
Duration: 1:14:44
Speaker: : Alfredo Canziani

Course:
This lecture covers the concepts of gradient descent, stochastic gradient descent, and momentum. It is a part of the Deep Learning Course at NYU's Center for Data Science. Prerequisites for this module include: Models 1-7 of this course and an Introduction to Data Science or a Graduate Level Machine Learning course.
Difficulty level: Advanced
Duration: 1:29:05
Speaker: : Aaron DeFazio

Course:
This lecture continues on the topic of descent from the previous lesson, Optimization I. This lesson is a part of the Deep Learning Course at NYU's Center for Data Science. Prerequisites for this module include: Models 1-7 of this course and an Introduction to Data Science or a Graduate Level Machine Learning course.
Difficulty level: Advanced
Duration: 1:51:32
Speaker: : Alfredo Canziani

Course:
In this lesson, users can follow along as a spaghetti script written in MATLAB is turned into understandable and reusable code living happily in a powerful GitHub repository.
Difficulty level: Beginner
Duration: 2:08:19
Speaker: : Agah Karakuzu

Course:
This presentation by the OHBM OpenScienceSIG covers common scenarios where Git can be extremely valuable. The essentials covered include cloning a repository and keeping it up to date, how to create and use your own repository, and how to contribute to other projects via forking and pull requests.
Difficulty level: Beginner
Duration: 51:55
Speaker: : Saskia Bollmann, Steffen Bollmann

Course:
This lesson consists of a talk about the history and future of academic publishing and the need for transparency, as well as a live demo of an alpha version of NeuroLibre, a preprint server that goes beyond the PDF to complement research articles. This video was part of a virutal QBIN SciComm seminar.
Difficulty level: Beginner
Duration: 00:53:35
Speaker: : Nikola Stikov and Agah Karakuzu

This session discussed the secret life of your dataset metadata: the ways in which, for many years to come, it will work non-stop to foster the visibility, reach, and impact of your work. We explored how metadata will help your dataset travel through the global research infrastructure, and how data repositories and discovery services can use this metadata to help launch your dataset into the world.
Difficulty level: Beginner
Duration: 59:58
Speaker: : Alicia Urquidi Díaz, Kelly Stahis
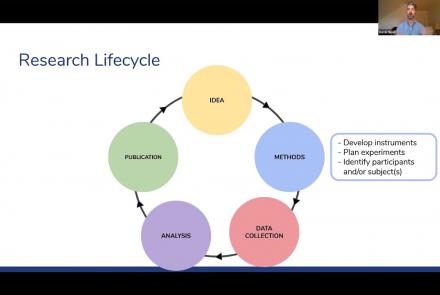
The Open Science Framework (OSF) provides avenues for researchers to design a study, as well as collect, analyze, and store data, manage collaborators, and publish research materials. In this webinar, attendees will learn about the many features of the OSF and develop strategies for using the tool within the context of their own research projects. The discussion will be framed around how to best utilize the OSF while also implementing data management and open science best practices.
Difficulty level: Beginner
Duration: 1:09:33
Speaker: : Kevin Read
Course:
In response to a growing need in the neuroscience community for concrete guidance concerning ethically sound and pragmatically feasible open data-sharing, the CONP has created an ‘Ethics Toolkit’. These documents (links found below in 'Documents' section) are meant to help researchers identify key elements in the design and conduct of their projects that are often required for the open sharing of neuroscience data, such as model consent language and approaches to de-identification.
This guidance is the product of extended discussions and careful drafting by the CONP Ethics and Governance Committee that considers both Canadian and international ethical frameworks and research practice. The best way to cite these resources is with their associated Zenodo DOI:
![]()
Difficulty level: Beginner
Duration:
Speaker: :

Course:
This lesson gives a quick walkthrough the Tidyverse, an "opinionated" collection of R packages designed for data science, including the use of readr, dplyr, tidyr, and ggplot2.
Difficulty level: Beginner
Duration: 1:01:39
Speaker: : Thomas Mock

Course:
As a part of NeuroHackademy 2020, Elizabeth DuPre gives a lecture on "Nilearn", a python package that provides flexible statistical and machine-learning tools for brain volumes by leveraging the scikit-learn Python toolbox for multivariate statistics. This includes predictive modelling, classification, decoding, and connectivity analysis.
This video is courtesy of the University of Washington eScience Institute.
Difficulty level: Beginner
Duration: 01:49:18
Speaker: : Elizabeth DuPre

Course:
Presented by the OHBM OpenScienceSIG, this lesson covers how containers can be useful for running the same software on different platforms and sharing analysis pipelines with other researchers.
Difficulty level: Beginner
Duration: 01:21:59
Speaker: : Tom Shaw & Steffen Bollmann

Course:
DataLad is a versatile data management and data publication multi-tool. In this session, you can learn the basic concepts and commands for version control and reproducible data analysis. You’ll get to see, create, and install DataLad datasets of many shapes and sizes, master local version workflows and provenance-captured analysis-execution, and you will get ideas for your next data analysis project.
Difficulty level: Beginner
Duration: 01:29:08
Speaker: : Adina Wagner

Course:
This lesson gives a general introduction to the essentials of navigating through a Bash terminal environment. The lesson is based on the Software Carpentries "Introduction to the Shell" and was given in the context of the BrainHack School 2020.
Difficulty level: Beginner
Duration: 1:12:22
Speaker: : Ross Markello

Course:
This lesson covers Python applications to data analysis, demonstrating why it has become ubiquitous in data science and neuroscience. The lesson was given in the context of the BrainHack School 2020.
Difficulty level: Beginner
Duration: 2:38:45
Speaker: : Ross Markello

Course:
This lesson gives a tour of how popular virtualization tools like Docker and Singularity are playing a crucial role in improving reproducibility and enabling high-performance computing in neuroscience.
Difficulty level: Beginner
Duration: 2:51:34
Speaker: : Peer Herholz