Lesson type
Difficulty level

Course:
The state of the field regarding the diagnosis and treatment of major depressive disorder (MDD) is discussed. Current challenges and opportunities facing the research and clinical communities are outlined, including appropriate quantitative and qualitative analyses of the heterogeneity of biological, social, and psychiatric factors which may contribute to MDD.
Difficulty level: Beginner
Duration: 1:29:28
Speaker: : Brett Jones, Victor Tang

This lesson gives a description of the BrainHealth Databank, a repository of many types of health-related data, whose aim is to accelerate research, improve care, and to help better understand and diagnose mental illness, as well as develop new treatments and prevention strategies.
This lesson corresponds to slides 46-78 of the PDF below.
Difficulty level: Beginner
Duration: 1:12:25
Speaker: : Joanna Yu

This lesson describes not only the need for precision medicine, but also the current state of the methods, pharmacogenetic approaches, utility and implementation of such care today.
This lesson corresponds to slides 1-50 of the PowerPoint below.
Difficulty level: Beginner
Duration: 1:24:30
Speaker: : Dan Felsky

This lecture discusses what defines an integrative approach regarding research and methods, including various study designs and models which are appropriate choices when attempting to bridge data domains; a necessity when whole-person modelling.
Difficulty level: Beginner
Duration: 1:28:14
Speaker: : Dan Felsky

In this session the Medical Informatics Platform (MIP) federated analytics is presented. The current and future analytical tools implemented in the MIP will be detailed along with the constructs, tools, processes, and restrictions that formulate the solution provided. MIP is a platform providing advanced federated analytics for diagnosis and research in clinical neuroscience research. It is targeting clinicians, clinical scientists and clinical data scientists. It is designed to help adopt advanced analytics, explore harmonized medical data of neuroimaging, neurophysiological and medical records as well as research cohort datasets, without transferring original clinical data. It can be perceived as a virtual database that seamlessly presents aggregated data from distributed sources, provides access and analyze imaging and clinical data, securely stored in hospitals, research archives and public databases. It leverages and re-uses decentralized patient data and research cohort datasets, without transferring original data. Integrated statistical analysis tools and machine learning algorithms are exposed over harmonized, federated medical data.
Difficulty level: Intermediate
Duration: 15:05
Speaker: : Giorgos Papanikos

The Medical Informatics Platform (MIP) is a platform providing federated analytics for diagnosis and research in clinical neuroscience research. The federated analytics is possible thanks to a distributed engine that executes computations and transfers information between the members of the federation (hospital nodes). In this talk the speaker will describe the process of designing and implementing new analytical tools, i.e. statistical and machine learning algorithms. Mr. Sakellariou will further describe the environment in which these federated algorithms run, the challenges and the available tools, the principles that guide its design and the followed general methodology for each new algorithm. One of the most important challenges which are faced is to design these tools in a way that does not compromise the privacy of the clinical data involved. The speaker will show how to address the main questions when designing such algorithms: how to decompose and distribute the computations and what kind of information to exchange between nodes, in order to comply with the privacy constraint mentioned above. Finally, also the subject of validating these federated algorithms will be briefly touched.
Difficulty level: Intermediate
Duration: 20:26
Speaker: : Jason Skellariou

The Medical Informatics Platform (MIP) Dementia had been installed in several memory clinics across Europe allowing them to federate their real-world databases. Research open access databases had also been integrated such as ADNI (Alzheimer’s Dementia Neuroimaging Initiative), reaching a cumulative case load of more than 5,000 patients (major cognitive disorder due to Alzheimer’s disease, other major cognitive disorder, minor cognitive disorder, controls). The statistic and machine learning tools implemented in the MIP allowed researchers to conduct easily federated analyses among Italian memory clinics (Redolfi et al. 2020) and also across borders between the French (Lille), the Swiss (Lausanne) and the Italian (Brescia) datasets.
Difficulty level: Intermediate
Duration: 16:44
Speaker: : Mélanie Leroy
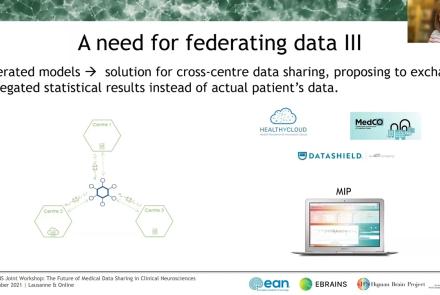
This talks presents ethics requirements of the Medical Informatics Platform, a data sharing platform for medical data using data federation mechanisms. The talk presents how the Medical Informatics Platform (MIP) works and which ethical requirements need to be considered when working with federated data.
Difficulty level: Intermediate
Duration: 16:25
Speaker: : Erika Borcel

This lecture talks about the usage of knowledge graphs in hospitals and related challenges of semantic interoperability.
Difficulty level: Intermediate
Duration: 24:32
Speaker: : Cristophe Gaudet-Blavignac

This lecture discusses risk-based anonymization approaches for medical research.
Difficulty level: Intermediate
Duration: 15:43
Speaker: : Fabian Prasser

This lesson introduces concepts and practices surrounding reference atlases for the mouse and rat brains. Additionally, this lesson provides discussion around examples of data systems employed to organize neuroscience data collections in the context of reference atlases as well as analytical workflows applied to the data.
Difficulty level: Beginner
Duration: 03:04:29
Speaker: :

This talk covers EBRAINS, an open research infrastructure that gathers data, tools and computing facilities for brain-related research, built with interoperability at the core.
Difficulty level: Beginner
Duration: 8:22
Speaker: : Petra Ritter

This lesson provides an introduction to the European open research infrastructure EBRAINS and its digital brain atlas resources.
Difficulty level: Beginner
Duration: 27:45
Speaker: : Trygve Leergard

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman

This lesson describes a definitional framework for fairness and health equity in the age of the algorithm. While acknowledging the impressive capability of machine learning to positively affect health equity, this talk outlines potential (and actual) pitfalls which come with such powerful tools, ultimately making the case for collaborative, interdisciplinary, and transparent science as a way to operationalize fairness in health equity.
Difficulty level: Beginner
Duration: 1:06:35
Speaker: : Laura Sikstrom

This lesson is the first part of a three-part series on the development of neuroinformatic infrastructure to ensure compliance with European data privacy standards and laws.
Difficulty level: Beginner
Duration: 1:10:05
Speaker: : Michael Schirner

This is the second of three lectures around current challenges and opportunities facing neuroinformatic infrastructure for handling sensitive data.
Difficulty level: Beginner
Duration: 48:26
Speaker: : Michael Schirner

This lesson contains the first part of the lecture Data Science and Reproducibility. You will learn about the development of data science and what the term currently encompasses, as well as how neuroscience and data science intersect.
Difficulty level: Beginner
Duration: 32:18
Speaker: : Ariel Rokem

This lecture gives a tour of what neuroethics is and how it applies to neuroscience and neurotechnology, while also addressing justice concerns within both fields.
Difficulty level: Beginner
Duration: 58:45
Speaker: : Tim Brown

This lecture presents selected theories of ethics as applied to questions raised by the Human Brain Project.
Difficulty level: Beginner
Duration: 38:49
Speaker: : Christine Mitchell