Lesson type
Difficulty level

This lightning talk describes an automated pipline for positron emission tomography (PET) data.
Difficulty level: Intermediate
Duration: 7:27
Speaker: : Soodeh Moallemian
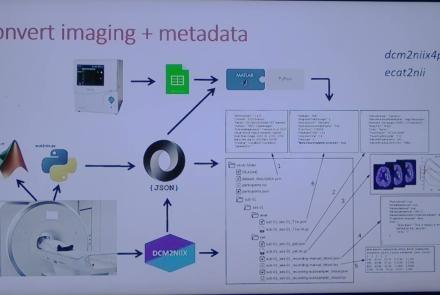
This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 9:23
Speaker: : Cyril Pernet

This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 41:04
Speaker: : Martin Nørgaard
This session dives into practical PET tooling on BIDS data—showing how to run motion correction, register PET↔MRI, extract time–activity curves, and generate standardized PET-BIDS derivatives with clear QC reports. It introduces modular BIDS Apps (head-motion correction, TAC extraction), a full pipeline (PETPrep), and a PET/MRI defacer, with guidance on parameters, outputs, provenance, and why Dockerized containers are the reliable way to run them at scale.
Difficulty level: Intermediate
Duration: 1:05:38
Speaker: : Martin Nørgaard

This session introduces two PET quantification tools—bloodstream for processing arterial blood data and kinfitr for kinetic modeling and quantification—built to work with BIDS/BIDS-derivatives and containers. Bloodstream fuses autosampler and manual measurements (whole blood, plasma, parent fraction) using interpolation or fitted models (incl. hierarchical GAMs) to produce a clean arterial input function (AIF) and whole-blood curves with rich QC reports ready. TAC data (e.g., from PETPrep) and blood (e.g., from bloodstream) can be ingested using kinfitr to run reproducible, GUI-driven analyses: define combined ROIs, calculate weighting factors, estimate blood–tissue delay, choose and chain models (e.g., 2TCM → 1TCM with parameter inheritance), and export parameters/diagnostics. Both are available as Docker apps; workflows emphasize configuration files, reports, and standard outputs to support transparency and reuse.
Difficulty level: Intermediate
Duration: 1:20:56
Speaker: : Granville Matheson

This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz

Course:
This module covers many of the types of non-invasive neurotech and neuroimaging devices including electroencephalography (EEG), electromyography (EMG), electroneurography (ENG), magnetoencephalography (MEG), and more.
Difficulty level: Beginner
Duration: 13:36
Speaker: : Harrison Canning

This lecture covers the emergence of cognitive science after the Second World War as an interdisciplinary field for studying the mind, with influences from anthropology, cybernetics, and artificial intelligence.
Difficulty level: Beginner
Duration: 51:07
Speaker: : Paul F.M.J. Verschure

This lecture provides an introduction to Plato’s concept of rationality and Aristotle’s concept of empiricism, and the enduring discussion between rationalism and empiricism to this day.
Difficulty level: Beginner
Duration: 1:13:45
Speaker: : Paul F.M.J. Verschure

This lecture covers different perspectives on the study of the mental, focusing on the difference between Mind and Brain.
Difficulty level: Beginner
Duration: 1:16:30
Speaker: : Paul F.M.J. Verschure

This lecture goes into further detail about the hard problem of developing a scientific discipline for subjective consciousness.
Difficulty level: Beginner
Duration: 58:03
Speaker: : Paul F.M.J. Verschure

This lecture outlines various approaches to studying Mind, Brain, and Behavior.
Difficulty level: Beginner
Duration: 1:02:34
Speaker: : Paul F.M.J. Verschure

This is the first of two workshops on reproducibility in science, during which participants are introduced to concepts of FAIR and open science. After discussing the definition of and need for FAIR science, participants are walked through tutorials on installing and using Github and Docker, the powerful, open-source tools for versioning and publishing code and software, respectively.
Difficulty level: Intermediate
Duration: 1:20:58
Speaker: : Erin Dickie and Sejal Patel

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This is a hands-on tutorial on PLINK, the open source whole genome association analysis toolset. The aims of this tutorial are to teach users how to perform basic quality control on genetic datasets, as well as to identify and understand GWAS summary statistics.
Difficulty level: Intermediate
Duration: 1:27:18
Speaker: : Dan Felsky

This is a tutorial on using the open-source software PRSice to calculate a set of polygenic risk scores (PRS) for a study sample. Users will also learn how to read PRS into R, visualize distributions, and perform basic association analyses.
Difficulty level: Intermediate
Duration: 1:53:34
Speaker: : Dan Felsky

Course:
Maximize Your Research With Cloud Workspaces is a talk aimed at researchers who are looking for innovative ways to set up and execute their life science data analyses in a collaborative, extensible, open-source cloud environment. This panel discussion is brought to you by MetaCell and scientists from leading universities who share their experiences of advanced analysis and collaborative learning through the Cloud.
Difficulty level: Beginner
Duration: 55:43

This talk enumerates the challenges regarding data accessibility and reusability inherent in the current scientific publication system, and discusses novel approaches to these challenges, such as the EBRAINS Live Papers platform.
Difficulty level: Beginner
Duration: 18:08
Speaker: : Andrew Davison

In this lesson, you will learn about how team science unfolds in practice, as well as what are the standards and best practices used by teams, and how well these best practices function and support scientific output.
Difficulty level: Beginner
Duration: 15:21
Speaker: : Hannah Bayer

In this lesson, you will learn about approaches to make the field of neuroscience more open and fair, particularly regarding the integration of equality, diversity, and inclusion (EDI) as guiding principles for team collaboration.
Difficulty level: Beginner
Duration: 14:11
Speaker: : Karin Grasenick