Lesson type
Difficulty level

This lesson describes spike timing-dependent plasticity (STDP), a biological process that adjusts the strength of connections between neurons in the brain, and how one can implement or mimic this process in a computational model. You will also find links for practical exercises at the bottom of this page.
Difficulty level: Intermediate
Duration: 12:50
Speaker: : Dan Goodman

This lesson provides a brief introduction to the Computational Modeling of Neuronal Plasticity.
Difficulty level: Intermediate
Duration: 0:40
Speaker: : Florence I. Kleberg

In this lesson, you will be introducted to a type of neuronal model known as the leaky integrate-and-fire (LIF) model.
Difficulty level: Intermediate
Duration: 1:23
Speaker: : Florence I. Kleberg

This lesson goes over various potential inputs to neuronal synapses, loci of neural communication.
Difficulty level: Intermediate
Duration: 1:20
Speaker: : Florence I. Kleberg

This lesson describes the how and why behind implementing integration time steps as part of a neuronal model.
Difficulty level: Intermediate
Duration: 1:08
Speaker: : Florence I. Kleberg
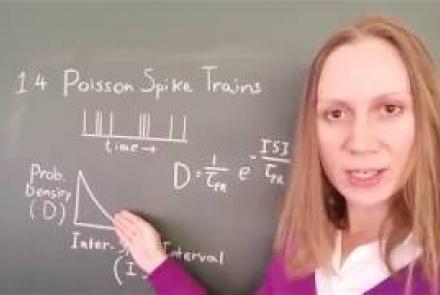
In this lesson, you will learn about neural spike trains which can be characterized as having a Poisson distribution.
Difficulty level: Intermediate
Duration: 1:18
Speaker: : Florence I. Kleberg

This lesson covers spike-rate adaptation, the process by which a neuron's firing pattern decays to a low, steady-state frequency during the sustained encoding of a stimulus.
Difficulty level: Intermediate
Duration: 1:26
Speaker: : Florence I. Kleberg

This lesson provides a brief explanation of how to implement a neuron's refractory period in a computational model.
Difficulty level: Intermediate
Duration: 0:42
Speaker: : Florence I. Kleberg

In this lesson, you will learn a computational description of the process which tunes neuronal connectivity strength, spike-timing-dependent plasticity (STDP).
Difficulty level: Intermediate
Duration: 2:40
Speaker: : Florence I. Kleberg

This lesson reviews theoretical and mathematical descriptions of correlated spike trains.
Difficulty level: Intermediate
Duration: 2:54
Speaker: : Florence I. Kleberg

This lesson investigates the effect of correlated spike trains on spike-timing dependent plasticity (STDP).
Difficulty level: Intermediate
Duration: 1:43
Speaker: : Florence I. Kleberg

This lesson goes over synaptic normalisation, the homeostatic process by which groups of weighted inputs scale up or down their biases.
Difficulty level: Intermediate
Duration: 2:58
Speaker: : Florence I. Kleberg

In this lesson, you will learn about the intrinsic plasticity of single neurons.
Difficulty level: Intermediate
Duration: 2:08
Speaker: : Florence I. Kleberg

This lesson covers short-term facilitation, a process whereby a neuron's synaptic transmission is enhanced for a short (sub-second) period.
Difficulty level: Intermediate
Duration: 1:58
Speaker: : Florence I. Kleberg

This lesson describes short-term depression, a reduction of synaptic information transfer between neurons.
Difficulty level: Intermediate
Duration: 1:40
Speaker: : Florence I. Kleberg

This lesson briefly wraps up the course on Computational Modeling of Neuronal Plasticity.
Difficulty level: Intermediate
Duration: 0:37
Speaker: : Florence I. Kleberg

This talks discusses data sharing in the context of dementia. It explains why data sharing in dementia is important, how data is usually shared in the field and illustrates two examples: the Netherlands Consortium Dementia cohorts and the European Platform for Neurodegenerative Diseases.
Difficulty level: Intermediate
Duration: 21:21
Speaker: : Pieter Jelle Visser

The Medical Informatics Platform (MIP) Dementia had been installed in several memory clinics across Europe allowing them to federate their real-world databases. Research open access databases had also been integrated such as ADNI (Alzheimer’s Dementia Neuroimaging Initiative), reaching a cumulative case load of more than 5,000 patients (major cognitive disorder due to Alzheimer’s disease, other major cognitive disorder, minor cognitive disorder, controls). The statistic and machine learning tools implemented in the MIP allowed researchers to conduct easily federated analyses among Italian memory clinics (Redolfi et al. 2020) and also across borders between the French (Lille), the Swiss (Lausanne) and the Italian (Brescia) datasets.
Difficulty level: Intermediate
Duration: 16:44
Speaker: : Mélanie Leroy

The number of patients with dementia is estimated to increase given the aging population. This will lead to a number of challenges in the future in terms of diagnosis and care for patients with dementia. To meet these needs such as early diagnsosis and development of prognostic biomarkers, large datasets, such as the federated datasets on dementia. The EAN Dementia and cognitive disorders scientific panel can play an important role as coordinator and connecting panel members who wish to participate in e.g. consortia.
Difficulty level: Intermediate
Duration: 15:39
Speaker: : Kristian Steen Frederiksen

This lecture provides an overview of some of the essential concepts in neuropharmacology (e.g. receptor binding, agonism, antagonism), an introduction to pharmacodynamics and pharmacokinetics, and an overview of the drug discovery process relative to diseases of the central nervous system.
Difficulty level: Beginner
Duration: 45:47
Speaker: : Sandra Santos-Sierra