Lesson type
Difficulty level

This lesson provides an overview of the current status in the field of neuroscientific ontologies, presenting examples of data organization and standards, particularly from neuroimaging and electrophysiology.
Difficulty level: Intermediate
Duration: 33:41
Speaker: : Yaroslav O. Halchenko

This lesson continues from part one of the lecture Ontologies, Databases, and Standards, diving deeper into a description of ontologies and knowledg graphs.
Difficulty level: Intermediate
Duration: 50:18
Speaker: : Jeff Grethe

This lecture covers the NIDM data format within BIDS to make your datasets more searchable, and how to optimize your dataset searches.
Difficulty level: Beginner
Duration: 12:33
Speaker: : David Keator
This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz

This lecture discusses the FAIR principles as they apply to electrophysiology data and metadata, the building blocks for community tools and standards, platforms and grassroots initiatives, and the challenges therein.
Difficulty level: Beginner
Duration: 8:11
Speaker: : Thomas Wachtler
This lecture discusses how to standardize electrophysiology data organization to move towards being more FAIR.
Difficulty level: Beginner
Duration: 15:51
Speaker: : Sylvain Takerkart

Course:
The International Brain Initiative (IBI) is a consortium of the world’s major large-scale brain initiatives and other organizations with a vested interest in catalyzing and advancing neuroscience research through international collaboration and knowledge sharing. This workshop introduces the IBI, the efforts of the Data Standards and Sharing Working Group, and keynote lectures on the impact of data standards and sharing on large-scale brain projects, as well as a discussion on prospects and needs for neural data sharing.
Difficulty level: Intermediate
Duration: 2:06:58

Course:
This lecture introduces neuroscience concepts and methods such as fMRI, visual respones in BOLD data, and the eccentricity of visual receptive fields.
Difficulty level: Intermediate
Duration: 7:15
Speaker: : Mike X. Cohen

Course:
In this tutorial, users learn how to compute and visualize a t-test on experimental condition differences.
Difficulty level: Intermediate
Duration: 17:54
Speaker: : Mike X. Cohen

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This is a hands-on tutorial on PLINK, the open source whole genome association analysis toolset. The aims of this tutorial are to teach users how to perform basic quality control on genetic datasets, as well as to identify and understand GWAS summary statistics.
Difficulty level: Intermediate
Duration: 1:27:18
Speaker: : Dan Felsky

Course:
This video will document how to run a correlation analysis between the gray matter volume of two different structures using the output from brainlife app-freesurfer-stats.
Difficulty level: Beginner
Duration: 1:33
Speaker: :

As the previous lesson of this course described how researchers acquire neural data, this lesson will discuss how to go about interpreting and analysing the data.
Difficulty level: Intermediate
Duration: 9:24
Speaker: : Marcus Ghosh

In this lesson, you will learn about one particular aspect of decision making: reaction times. In other words, how long does it take to take a decision based on a stream of information arriving continuously over time?
Difficulty level: Intermediate
Duration: 6:01
Speaker: : Dan Goodman

In this session the Medical Informatics Platform (MIP) federated analytics is presented. The current and future analytical tools implemented in the MIP will be detailed along with the constructs, tools, processes, and restrictions that formulate the solution provided. MIP is a platform providing advanced federated analytics for diagnosis and research in clinical neuroscience research. It is targeting clinicians, clinical scientists and clinical data scientists. It is designed to help adopt advanced analytics, explore harmonized medical data of neuroimaging, neurophysiological and medical records as well as research cohort datasets, without transferring original clinical data. It can be perceived as a virtual database that seamlessly presents aggregated data from distributed sources, provides access and analyze imaging and clinical data, securely stored in hospitals, research archives and public databases. It leverages and re-uses decentralized patient data and research cohort datasets, without transferring original data. Integrated statistical analysis tools and machine learning algorithms are exposed over harmonized, federated medical data.
Difficulty level: Intermediate
Duration: 15:05
Speaker: : Giorgos Papanikos

The Medical Informatics Platform (MIP) is a platform providing federated analytics for diagnosis and research in clinical neuroscience research. The federated analytics is possible thanks to a distributed engine that executes computations and transfers information between the members of the federation (hospital nodes). In this talk the speaker will describe the process of designing and implementing new analytical tools, i.e. statistical and machine learning algorithms. Mr. Sakellariou will further describe the environment in which these federated algorithms run, the challenges and the available tools, the principles that guide its design and the followed general methodology for each new algorithm. One of the most important challenges which are faced is to design these tools in a way that does not compromise the privacy of the clinical data involved. The speaker will show how to address the main questions when designing such algorithms: how to decompose and distribute the computations and what kind of information to exchange between nodes, in order to comply with the privacy constraint mentioned above. Finally, also the subject of validating these federated algorithms will be briefly touched.
Difficulty level: Intermediate
Duration: 20:26
Speaker: : Jason Skellariou

The Medical Informatics Platform (MIP) Dementia had been installed in several memory clinics across Europe allowing them to federate their real-world databases. Research open access databases had also been integrated such as ADNI (Alzheimer’s Dementia Neuroimaging Initiative), reaching a cumulative case load of more than 5,000 patients (major cognitive disorder due to Alzheimer’s disease, other major cognitive disorder, minor cognitive disorder, controls). The statistic and machine learning tools implemented in the MIP allowed researchers to conduct easily federated analyses among Italian memory clinics (Redolfi et al. 2020) and also across borders between the French (Lille), the Swiss (Lausanne) and the Italian (Brescia) datasets.
Difficulty level: Intermediate
Duration: 16:44
Speaker: : Mélanie Leroy
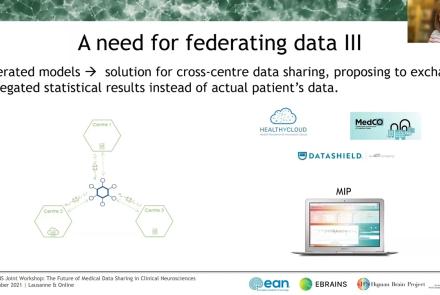
This talks presents ethics requirements of the Medical Informatics Platform, a data sharing platform for medical data using data federation mechanisms. The talk presents how the Medical Informatics Platform (MIP) works and which ethical requirements need to be considered when working with federated data.
Difficulty level: Intermediate
Duration: 16:25
Speaker: : Erika Borcel

This lecture talks about the usage of knowledge graphs in hospitals and related challenges of semantic interoperability.
Difficulty level: Intermediate
Duration: 24:32
Speaker: : Cristophe Gaudet-Blavignac

This lecture discusses risk-based anonymization approaches for medical research.
Difficulty level: Intermediate
Duration: 15:43
Speaker: : Fabian Prasser