Lesson type
Difficulty level

This lightning talk describes an automated pipline for positron emission tomography (PET) data.
Difficulty level: Intermediate
Duration: 7:27
Speaker: : Soodeh Moallemian
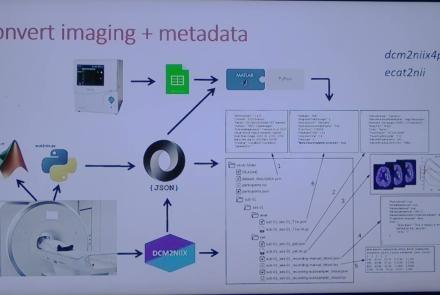
This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 9:23
Speaker: : Cyril Pernet

This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 41:04
Speaker: : Martin Nørgaard
This session dives into practical PET tooling on BIDS data—showing how to run motion correction, register PET↔MRI, extract time–activity curves, and generate standardized PET-BIDS derivatives with clear QC reports. It introduces modular BIDS Apps (head-motion correction, TAC extraction), a full pipeline (PETPrep), and a PET/MRI defacer, with guidance on parameters, outputs, provenance, and why Dockerized containers are the reliable way to run them at scale.
Difficulty level: Intermediate
Duration: 1:05:38
Speaker: : Martin Nørgaard

This session introduces two PET quantification tools—bloodstream for processing arterial blood data and kinfitr for kinetic modeling and quantification—built to work with BIDS/BIDS-derivatives and containers. Bloodstream fuses autosampler and manual measurements (whole blood, plasma, parent fraction) using interpolation or fitted models (incl. hierarchical GAMs) to produce a clean arterial input function (AIF) and whole-blood curves with rich QC reports ready. TAC data (e.g., from PETPrep) and blood (e.g., from bloodstream) can be ingested using kinfitr to run reproducible, GUI-driven analyses: define combined ROIs, calculate weighting factors, estimate blood–tissue delay, choose and chain models (e.g., 2TCM → 1TCM with parameter inheritance), and export parameters/diagnostics. Both are available as Docker apps; workflows emphasize configuration files, reports, and standard outputs to support transparency and reuse.
Difficulty level: Intermediate
Duration: 1:20:56
Speaker: : Granville Matheson

This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz

Course:
This module covers many of the types of non-invasive neurotech and neuroimaging devices including electroencephalography (EEG), electromyography (EMG), electroneurography (ENG), magnetoencephalography (MEG), and more.
Difficulty level: Beginner
Duration: 13:36
Speaker: : Harrison Canning

Course:
Maximize Your Research With Cloud Workspaces is a talk aimed at researchers who are looking for innovative ways to set up and execute their life science data analyses in a collaborative, extensible, open-source cloud environment. This panel discussion is brought to you by MetaCell and scientists from leading universities who share their experiences of advanced analysis and collaborative learning through the Cloud.
Difficulty level: Beginner
Duration: 55:43

This brief video provides an introduction to the third session of INCF's Neuroinformatics Assembly 2023, focusing on how to streamling cross-platform data integration in a neuroscientific context.
Difficulty level: Beginner
Duration: 5:55
Speaker: : Bing-Xing Huo

This talk describes the challenges to sustained operability and success of consortia, why many of these groups flounder after just a few years, and what steps can be taken to mitigate such outcomes.
Difficulty level: Beginner
Duration: 18:29
Speaker: : Maryann Martone

This talk discusses the BRAIN Initiative Cell Atlas Network (BICAN), taking a look specifically at how this network approaches the design, development, and maintenance of specimen and sequencing library portals.
Difficulty level: Beginner
Duration: 15:08
Speaker: : GQ Zhang

In this talk, you will hear about the challenges and costs of being FAIR in the many scientific fields, as well as opportunities to transform the ecology of the academic crediting system.
Difficulty level: Beginner
Duration: 14:56
Speaker: : Zefan Zheng

This brief talk describes the challenge of global data sharing and governance, as well as efforts of the the Brain Research International Data Governance & Exchange (BRIDGE) to develop ready-made workflows to share data globally.
Difficulty level: Beginner
Duration: 6:47
Speaker: : Kimberly Ray

This talk describes how to use DataLad for your data management and curation techniques when dealing with animal datasets, which often contain several disparate types of data, including MRI, microscopy, histology, electrocorticography, and behavioral measurements.
Difficulty level: Beginner
Duration: 3:35
Speaker: : Aref Kalantari Sarcheshmeh

This brief talk covers an analysis technique for multi-band, multi-echo fMRI data, applying a denoising framework which can be used in an automated pipeline.
Difficulty level: Beginner
Duration: 4:45
Speaker: : David Abbott

This lecture goes into detailed description of how to process workflows in the virtual research environment (VRE), including approaches for standardization, metadata, containerization, and constructing and maintaining scientific pipelines.
Difficulty level: Intermediate
Duration: 1:03:55
Speaker: : Patrik Bey

This lesson gives a quick introduction to the rest of this course, Research Workflows for Collaborative Neuroscience.
Difficulty level: Beginner
Duration: 3:23
Speaker: : Dimitri Yatsenko

This lesson provides an overview of how to conceptualize, design, implement, and maintain neuroscientific pipelines in via the cloud-based computational reproducibility platform Code Ocean.
Difficulty level: Beginner
Duration: 17:01
Speaker: : David Feng

This lesson provides an overview of how to construct computational pipelines for neurophysiological data using DataJoint.
Difficulty level: Beginner
Duration: 17:37
Speaker: : Dimitri Yatsenko

This talk describes approaches to maintaining integrated workflows and data management schema, taking advantage of the many open source, collaborative platforms already existing.
Difficulty level: Beginner
Duration: 15:15
Speaker: : Erik C. Johnson