Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This lesson gives a description of the BrainHealth Databank, a repository of many types of health-related data, whose aim is to accelerate research, improve care, and to help better understand and diagnose mental illness, as well as develop new treatments and prevention strategies.
This lesson corresponds to slides 46-78 of the PDF below.
Difficulty level: Beginner
Duration: 1:12:25
Speaker: : Joanna Yu

This lecture covers a lot of post-war developments in the science of the mind, focusing first on the cognitive revolution, and concluding with living machines.
Difficulty level: Beginner
Duration: 2:24:35
Speaker: : Paul F.M.J. Verschure
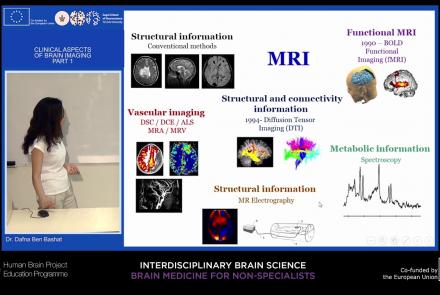
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

This lecture provides an overview of depression (epidemiology and course of the disorder), clinical presentation, somatic co-morbidity, and treatment options.
Difficulty level: Beginner
Duration: 37:51
Speaker: : Barbara Sperner-Unterweger

In this lesson, you will learn about how genetics can contribute to our understanding of psychiatric phenotypes.
Difficulty level: Beginner
Duration: 55:15
Speaker: : Sven Cichon

This lecture provides an overview of some of the essential concepts in neuropharmacology (e.g. receptor binding, agonism, antagonism), an introduction to pharmacodynamics and pharmacokinetics, and an overview of the drug discovery process relative to diseases of the central nervous system.
Difficulty level: Beginner
Duration: 45:47
Speaker: : Sandra Santos-Sierra
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier
Course:
This lesson discusses FAIR principles and methods currently in development for assessing FAIRness.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

Course:
This demonstration walks through how to import your data into MATLAB.
Difficulty level: Beginner
Duration: 6:10
Speaker: : MATLAB®

Course:
This lesson provides instruction regarding the various factors one must consider when preprocessing data, preparing it for statistical exploration and analyses.
Difficulty level: Beginner
Duration: 15:10
Speaker: : MATLAB®

Course:
This tutorial outlines, step by step, how to perform analysis by group and how to do change-point detection.
Difficulty level: Beginner
Duration: 2:49
Speaker: : MATLAB®

Course:
This tutorial walks through several common methods for visualizing your data in different ways depending on your data type.
Difficulty level: Beginner
Duration: 6:10
Speaker: : MATLAB®

Course:
This tutorial illustrates several ways to approach predictive modeling and machine learning with MATLAB.
Difficulty level: Beginner
Duration: 6:27
Speaker: : MATLAB®

Course:
This brief tutorial goes over how you can easily work with big data as you would with any size of data.
Difficulty level: Beginner
Duration: 3:55
Speaker: : MATLAB®

Course:
In this tutorial, you will learn how to deploy your models outside of your local MATLAB environment, enabling wider sharing and collaboration.
Difficulty level: Beginner
Duration: 3:52
Speaker: : MATLAB®

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

Course:
This lecture covers the needs and challenges involved in creating a FAIR ecosystem for neuroimaging research.
Difficulty level: Beginner
Duration: 12:26
Speaker: : Camille Maumet

This lecture covers how to make modeling workflows FAIR by working through a practical example, dissecting the steps within the workflow, and detailing the tools and resources used at each step.
Difficulty level: Beginner
Duration: 15:14
Speaker: : Salvador Dura-Bernal