Lesson type
Difficulty level

Course:
The state of the field regarding the diagnosis and treatment of major depressive disorder (MDD) is discussed. Current challenges and opportunities facing the research and clinical communities are outlined, including appropriate quantitative and qualitative analyses of the heterogeneity of biological, social, and psychiatric factors which may contribute to MDD.
Difficulty level: Beginner
Duration: 1:29:28
Speaker: : Brett Jones, Victor Tang

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This lesson gives a description of the BrainHealth Databank, a repository of many types of health-related data, whose aim is to accelerate research, improve care, and to help better understand and diagnose mental illness, as well as develop new treatments and prevention strategies.
This lesson corresponds to slides 46-78 of the PDF below.
Difficulty level: Beginner
Duration: 1:12:25
Speaker: : Joanna Yu

This lesson describes not only the need for precision medicine, but also the current state of the methods, pharmacogenetic approaches, utility and implementation of such care today.
This lesson corresponds to slides 1-50 of the PowerPoint below.
Difficulty level: Beginner
Duration: 1:24:30
Speaker: : Dan Felsky

This lecture discusses what defines an integrative approach regarding research and methods, including various study designs and models which are appropriate choices when attempting to bridge data domains; a necessity when whole-person modelling.
Difficulty level: Beginner
Duration: 1:28:14
Speaker: : Dan Felsky

This lecture covers the history of behaviorism and the ultimate challenge to behaviorism.
Difficulty level: Beginner
Duration: 1:19:08
Speaker: : Paul F.M.J. Verschure
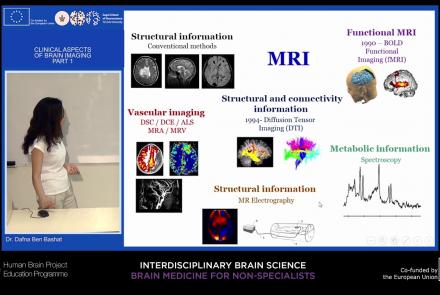
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

This lecture gives an introduction to the types of glial cells, homeostasis (influence of cerebral blood flow and influence on neurons), insulation and protection of axons (myelin sheath; nodes of Ranvier), microglia and reactions of the CNS to injury.
Difficulty level: Beginner
Duration: 40:32
Speaker: : Christine Bandtlow
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier
Course:
This lesson discusses FAIR principles and methods currently in development for assessing FAIRness.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

Course:
The lecture provides an overview of the core skills and practical solutions required to practice reproducible research.
Difficulty level: Beginner
Duration: 1:25:17
Speaker: : Fernando Perez

Course:
This lecture covers FAIR atlases, including their background and construction, as well as how they can be created in line with the FAIR principles.
Difficulty level: Beginner
Duration: 14:24
Speaker: : Heidi Kleven
Course:
This lecture covers the biomedical researcher's perspective on FAIR data sharing and the importance of finding better ways to manage large datasets.
Difficulty level: Beginner
Duration: 10:51
Speaker: : Adam Ferguson
Course:
This lecture covers the needs and challenges involved in creating a FAIR ecosystem for neuroimaging research.
Difficulty level: Beginner
Duration: 12:26
Speaker: : Camille Maumet
Course:
This lecture covers multiple aspects of FAIR neuroscience data: what makes it unique, the challenges to making it FAIR, the importance of overcoming these challenges, and how data governance comes into play.
Difficulty level: Beginner
Duration: 14:56
Speaker: : Damian Eke

This lecture covers how to make modeling workflows FAIR by working through a practical example, dissecting the steps within the workflow, and detailing the tools and resources used at each step.
Difficulty level: Beginner
Duration: 15:14
Speaker: : Salvador Dura-Bernal

This lecture covers the NIDM data format within BIDS to make your datasets more searchable, and how to optimize your dataset searches.
Difficulty level: Beginner
Duration: 12:33
Speaker: : David Keator
This lecture covers the processes, benefits, and challenges involved in designing, collecting, and sharing FAIR neuroscience datasets.
Difficulty level: Beginner
Duration: 11:35
Speaker: : Julie Boyle & Valentina Borghesani