Lesson type
Difficulty level

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman

This lesson describes a definitional framework for fairness and health equity in the age of the algorithm. While acknowledging the impressive capability of machine learning to positively affect health equity, this talk outlines potential (and actual) pitfalls which come with such powerful tools, ultimately making the case for collaborative, interdisciplinary, and transparent science as a way to operationalize fairness in health equity.
Difficulty level: Beginner
Duration: 1:06:35
Speaker: : Laura Sikstrom

Introduction of the Foundations of Machine Learning in Python course - Day 01.
High-Performance Computing and Analytics Lab, University of Bonn
Difficulty level: Beginner
Duration: 35:24
Speaker: : Elena Trunz

This lesson gives a brief introduction to the course Neuroscience for Machine Learners (Neuro4ML).
Difficulty level: Beginner
Duration: 1:25
Speaker: : Dan Goodman

This lesson covers the history of neuroscience and machine learning, and the story of how these two seemingly disparate fields are increasingly merging.
Difficulty level: Beginner
Duration: 12:25
Speaker: : Dan Goodman

In this lesson, you will learn about the current challenges facing the integration of machine learning and neuroscience.
Difficulty level: Beginner
Duration: 5:42
Speaker: : Dan Goodman

This lesson provides an overview of self-supervision as it relates to neural data tasks and the Mine Your Own vieW (MYOW) approach.
Difficulty level: Beginner
Duration: 25:50
Speaker: : Eva Dyer

Course:
This lesson provides a conceptual overview of the rudiments of machine learning, including its bases in traditional statistics and the types of questions it might be applied to. The lesson was presented in the context of the BrainHack School 2020.
Difficulty level: Beginner
Duration: 01:22:18
Speaker: : Estefany Suárez

Course:
This lesson presents advanced machine learning algorithms for neuroimaging, while addressing some real-world considerations related to data size and type.
Difficulty level: Beginner
Duration: 01:17:14
Speaker: : Gael Varoquaux

This talk covers the differences between applying HED annotation to fMRI datasets versus other neuroimaging practices, and also introduces an analysis pipeline using HED tags.
Difficulty level: Beginner
Duration: 22:52
Speaker: : Monique Denissen
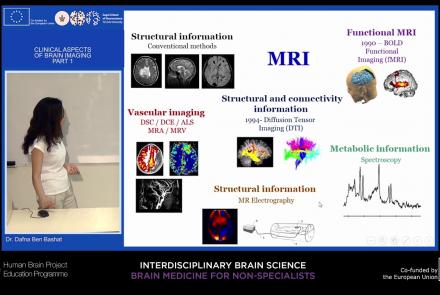
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

Course:
Longitudinal Online Research and Imaging System (LORIS) is a web-based data and project management software for neuroimaging research studies. It is an open source framework for storing and processing behavioural, clinical, neuroimaging and genetic data. LORIS also makes it easy to manage large datasets acquired over time in a longitudinal study, or at different locations in a large multi-site study.
Difficulty level: Beginner
Duration: 0:35
Speaker: : Samir Das

Course:
This talk covers the Neuroimaging Informatics Tools and Resources Clearinghouse (NITRC), a free one-stop-shop collaboratory for science researchers that need resources such as neuroimaging analysis software, publicly available data sets, or computing power.
Difficulty level: Beginner
Duration: 1:00:10
Speaker: : David Kennedy

Course:
BioImage Suite is an integrated image analysis software suite developed at Yale University. BioImage Suite has been extensively used at different labs at Yale since about 2001.
Difficulty level: Beginner
Duration: 01:47
Speaker: : BioImage Suite

Course:
Fibr is an app for quality control of diffusion MRI images from the Healthy Brain Network, a landmark mental health study that is collecting MRI images and other assessment data from 10,000 New York City area children. The purpose of the app is to train a computer algorithm to analyze the Healthy Brain Network dataset. By playing fibr, you are helping to teach the computer which images have sufficiently good quality and which images do not.
Difficulty level: Beginner
Duration: 02:26
Speaker: : Ariel Rokem

Course:
This lecture covers the needs and challenges involved in creating a FAIR ecosystem for neuroimaging research.
Difficulty level: Beginner
Duration: 12:26
Speaker: : Camille Maumet

This lecture covers the NIDM data format within BIDS to make your datasets more searchable, and how to optimize your dataset searches.
Difficulty level: Beginner
Duration: 12:33
Speaker: : David Keator
This lecture covers the processes, benefits, and challenges involved in designing, collecting, and sharing FAIR neuroscience datasets.
Difficulty level: Beginner
Duration: 11:35
Speaker: : Julie Boyle & Valentina Borghesani
This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz
This lecture covers the benefits and difficulties involved when re-using open datasets, and how metadata is important to the process.
Difficulty level: Beginner
Duration: 11:20
Speaker: : Elizabeth DuPre