Lesson type
Difficulty level

Course:
In this lesson you will learn how to simulate seizure events and epilepsy in The Virtual Brain. We will look at the paper On the Nature of Seizure Dynamics, which describes a new local model called the Epileptor, and apply this same model in The Virtual Brain. This is part 1 of 2 in a series explaining how to use the Epileptor. In this part, we focus on setting up the parameters.
Difficulty level: Beginner
Duration: 4:44
Speaker: : Paul Triebkorn

Manipulate the default connectome provided with TVB to see how structural lesions effect brain dynamics. In this hands-on session you will insert lesions into the connectome within the TVB graphical user interface (GUI). Afterwards, the modified connectome will be used for simulations and the resulting activity will be analysed using functional connectivity.
Difficulty level: Beginner
Duration: 31:22
Speaker: : Paul Triebkorn

Research Resource Identifiers (RRIDs) are ID numbers assigned to help researchers cite key resources (e.g., antibodies, model organisms, and software projects) in biomedical literature to improve the transparency of research methods.
Difficulty level: Beginner
Duration: 1:01:36
Speaker: : Maryann Martone

This video gives a short introduction to the EBRAINS data sharing platform, why it was developed, and how it contributes to open data sharing.
Difficulty level: Beginner
Duration: 17:32
Speaker: : Ida Aasebø

This video explains what metadata is, why it is important, and how you can organize your metadata to increase the FAIRness of your data on EBRAINS.
Difficulty level: Beginner
Duration: 17:23
Speaker: : Ulrike Schlegel

This video introduces the importance of writing a Data Descriptor to accompany your dataset on EBRAINS. It gives concrete examples on what information to include and highlights how this makes your data more FAIR.
Difficulty level: Beginner
Duration: 9:48
Speaker: : Ingrid Reiten

Course:
KnowledgeSpace (KS) is a data discoverability portal and neuroscience encyclopedia that was developed to make it easier for the neuroscience community to find publicly available datasets that adhere to the FAIR Principles and to provide an integrated view of neuroscience concepts found in Wikipedia and NeuroLex linked with PubMed and 17 of the world's leading neuroscience repositories. In short, KS provides a single point of entry where reseaerchers can search for a neuroscience concept of interest and receive results that include: i. a description of the term found in Wikipedia/NeuroLex, ii. links to publicly available datasets related to the concept of interest, and iii. up-to-date references that support the concept of interests found in PubMed. APIs are available so that developers of other neuroscience research infrastructures can integrate KS components in their infrastructures. If your repository or your favorite repository is not indexed in KS, please contact us.
Difficulty level: Beginner
Duration: 6:14
Speaker: : Heather Topple

In this lesson, users will learn about the importance of proper citation of software resources and tools used in neuroscientific research.
Difficulty level: Beginner
Duration: 58:00
Speaker: : Neil Chue Hong & Daniel Katz

Course:
The Mouse Phenome Database (MPD) provides access to primary experimental trait data, genotypic variation, protocols and analysis tools for mouse genetic studies. Data are contributed by investigators worldwide and represent a broad scope of phenotyping endpoints and disease-related traits in naïve mice and those exposed to drugs, environmental agents or other treatments. MPD ensures rigorous curation of phenotype data and supporting documentation using relevant ontologies and controlled vocabularies. As a repository of curated and integrated data, MPD provides a means to access/re-use baseline data, as well as allows users to identify sensitized backgrounds for making new mouse models with genome editing technologies, analyze trait co-inheritance, benchmark assays in their own laboratories, and many other research applications. MPD’s primary source of funding is NIDA. For this reason, a majority of MPD data is neuro- and behavior-related.
Difficulty level: Beginner
Duration: 55:36
Speaker: : Elissa Chesler

Course:
This lesson introduces the EEGLAB toolbox, as well as motivations for its use.
Difficulty level: Beginner
Duration: 15:32
Speaker: : Arnaud Delorme
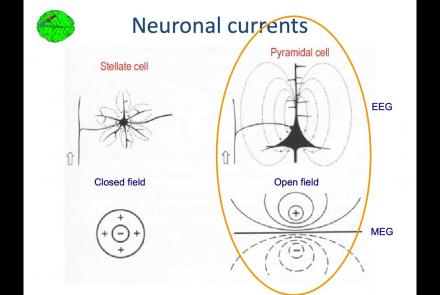
Course:
In this lesson, you will learn about the biological activity which generates and is measured by the EEG signal.
Difficulty level: Beginner
Duration: 6:53
Speaker: : Arnaud Delorme

Course:
This lesson goes over the characteristics of EEG signals when analyzed in source space (as opposed to sensor space).
Difficulty level: Beginner
Duration: 10:56
Speaker: : Arnaud Delorme

Course:
This lesson describes the development of EEGLAB as well as to what extent it is used by the research community.
Difficulty level: Beginner
Duration: 6:06
Speaker: : Arnaud Delorme

Course:
This lesson provides instruction as to how to build a processing pipeline in EEGLAB for a single participant.
Difficulty level: Beginner
Duration: 9:20
Speaker: :

Course:
Whereas the previous lesson of this course outlined how to build a processing pipeline for a single participant, this lesson discusses analysis pipelines for multiple participants simultaneously.
Difficulty level: Beginner
Duration: 10:55
Speaker: : Arnaud Delorme

Course:
In addition to outlining the motivations behind preprocessing EEG data in general, this lesson covers the first step in preprocessing data with EEGLAB, importing raw data.
Difficulty level: Beginner
Duration: 8:30
Speaker: : Arnaud Delorme

Course:
Continuing along the EEGLAB preprocessing pipeline, this tutorial walks users through how to import data events as well as EEG channel locations.
Difficulty level: Beginner
Duration: 11:53
Speaker: : Arnaud Delorme

Course:
This tutorial demonstrates how to re-reference and resample raw data in EEGLAB, why such steps are important or useful in the preprocessing pipeline, and how choices made at this step may affect subsequent analyses.
Difficulty level: Beginner
Duration: 11:48
Speaker: : Arnaud Delorme

Course:
This tutorial instructs users how to visually inspect partially pre-processed neuroimaging data in EEGLAB, specifically how to use the data browser to investigate specific channels, epochs, or events for removable artifacts, biological (e.g., eye blinks, muscle movements, heartbeat) or otherwise (e.g., corrupt channel, line noise).
Difficulty level: Beginner
Duration: 5:08
Speaker: : Arnaud Delorme

Course:
This tutorial provides instruction on how to use EEGLAB to further preprocess EEG datasets by identifying and discarding bad channels which, if left unaddressed, can corrupt and confound subsequent analysis steps.
Difficulty level: Beginner
Duration: 13:01
Speaker: : Arnaud Delorme