Lesson type
Difficulty level

This lecture covers the three big questions: What is the universe?, what is life?, and what is consciousness?
Difficulty level: Beginner
Duration: 1:07:52
Speaker: : Paul F.M.J. Verschure

This lecture outlines various approaches to studying Mind, Brain, and Behavior.
Difficulty level: Beginner
Duration: 1:02:34
Speaker: : Paul F.M.J. Verschure

This lecture covers the history of behaviorism and the ultimate challenge to behaviorism.
Difficulty level: Beginner
Duration: 1:19:08
Speaker: : Paul F.M.J. Verschure

This lecture covers various learning theories.
Difficulty level: Beginner
Duration: 1:00:42
Speaker: : Paul F.M.J. Verschure

Course:
An introduction to data management, manipulation, visualization, and analysis for neuroscience. Students will learn scientific programming in Python, and use this to work with example data from areas such as cognitive-behavioral research, single-cell recording, EEG, and structural and functional MRI. Basic signal processing techniques including filtering are covered. The course includes a Jupyter Notebook and video tutorials.
Difficulty level: Beginner
Duration: 1:09:16
Speaker: : Aaron J. Newman
Course:
The goal of computational modeling in behavioral and psychological science is using mathematical models to characterize behavioral (or neural) data. Over the past decade, this practice has revolutionized social psychological science (and neuroscience) by allowing researchers to formalize theories as constrained mathematical models and test specific hypotheses to explain unobservable aspects of complex social cognitive processes and behaviors. This course is composed of 4 modules in the format of Jupyter Notebooks. This course comprises lecture-based, discussion-based, and lab-based instruction. At least one-third of class sessions will be hands-on. We will discuss relevant book chapters and journal articles, and work with simulated and real data using the Python programming language (no prior programming experience necessary) as we survey some selected areas of research at the intersection of computational modeling and social behavior. These selected topics will span a broad set of social psychological abilities including (1) learning from and for others, (2) learning about others, and (3) social influence on decision-making and mental states. Rhoads, S. A. & Gan, L. (2022). Computational models of human social behavior and neuroscience - An open educational course and Jupyter Book to advance computational training. Journal of Open Source Education, 5(47), 146. https://doi.org/10.21105/jose.00146
Difficulty level: Intermediate
Duration:
Speaker: :

In this session the Medical Informatics Platform (MIP) federated analytics is presented. The current and future analytical tools implemented in the MIP will be detailed along with the constructs, tools, processes, and restrictions that formulate the solution provided. MIP is a platform providing advanced federated analytics for diagnosis and research in clinical neuroscience research. It is targeting clinicians, clinical scientists and clinical data scientists. It is designed to help adopt advanced analytics, explore harmonized medical data of neuroimaging, neurophysiological and medical records as well as research cohort datasets, without transferring original clinical data. It can be perceived as a virtual database that seamlessly presents aggregated data from distributed sources, provides access and analyze imaging and clinical data, securely stored in hospitals, research archives and public databases. It leverages and re-uses decentralized patient data and research cohort datasets, without transferring original data. Integrated statistical analysis tools and machine learning algorithms are exposed over harmonized, federated medical data.
Difficulty level: Intermediate
Duration: 15:05
Speaker: : Giorgos Papanikos

The Medical Informatics Platform (MIP) is a platform providing federated analytics for diagnosis and research in clinical neuroscience research. The federated analytics is possible thanks to a distributed engine that executes computations and transfers information between the members of the federation (hospital nodes). In this talk the speaker will describe the process of designing and implementing new analytical tools, i.e. statistical and machine learning algorithms. Mr. Sakellariou will further describe the environment in which these federated algorithms run, the challenges and the available tools, the principles that guide its design and the followed general methodology for each new algorithm. One of the most important challenges which are faced is to design these tools in a way that does not compromise the privacy of the clinical data involved. The speaker will show how to address the main questions when designing such algorithms: how to decompose and distribute the computations and what kind of information to exchange between nodes, in order to comply with the privacy constraint mentioned above. Finally, also the subject of validating these federated algorithms will be briefly touched.
Difficulty level: Intermediate
Duration: 20:26
Speaker: : Jason Skellariou

The Medical Informatics Platform (MIP) Dementia had been installed in several memory clinics across Europe allowing them to federate their real-world databases. Research open access databases had also been integrated such as ADNI (Alzheimer’s Dementia Neuroimaging Initiative), reaching a cumulative case load of more than 5,000 patients (major cognitive disorder due to Alzheimer’s disease, other major cognitive disorder, minor cognitive disorder, controls). The statistic and machine learning tools implemented in the MIP allowed researchers to conduct easily federated analyses among Italian memory clinics (Redolfi et al. 2020) and also across borders between the French (Lille), the Swiss (Lausanne) and the Italian (Brescia) datasets.
Difficulty level: Intermediate
Duration: 16:44
Speaker: : Mélanie Leroy
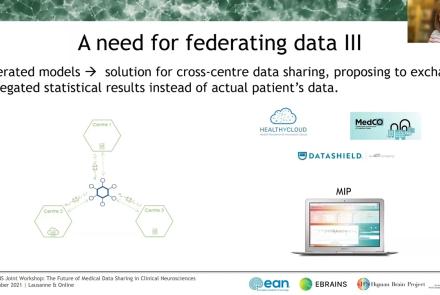
This talks presents ethics requirements of the Medical Informatics Platform, a data sharing platform for medical data using data federation mechanisms. The talk presents how the Medical Informatics Platform (MIP) works and which ethical requirements need to be considered when working with federated data.
Difficulty level: Intermediate
Duration: 16:25
Speaker: : Erika Borcel

This lecture talks about the usage of knowledge graphs in hospitals and related challenges of semantic interoperability.
Difficulty level: Intermediate
Duration: 24:32
Speaker: : Cristophe Gaudet-Blavignac

This lecture discusses risk-based anonymization approaches for medical research.
Difficulty level: Intermediate
Duration: 15:43
Speaker: : Fabian Prasser

This lesson introduces concepts and practices surrounding reference atlases for the mouse and rat brains. Additionally, this lesson provides discussion around examples of data systems employed to organize neuroscience data collections in the context of reference atlases as well as analytical workflows applied to the data.
Difficulty level: Beginner
Duration: 03:04:29
Speaker: :

This talk covers EBRAINS, an open research infrastructure that gathers data, tools and computing facilities for brain-related research, built with interoperability at the core.
Difficulty level: Beginner
Duration: 8:22
Speaker: : Petra Ritter

This lesson provides an introduction to the European open research infrastructure EBRAINS and its digital brain atlas resources.
Difficulty level: Beginner
Duration: 27:45
Speaker: : Trygve Leergard

Course:
This lesson is a general overview of overarching concepts in neuroinformatics research, with a particular focus on clinical approaches to defining, measuring, studying, diagnosing, and treating various brain disorders. Also described are the complex, multi-level nature of brain disorders and the data associated with them, from genes and individual cells up to cortical microcircuits and whole-brain network dynamics. Given the heterogeneity of brain disorders and their underlying mechanisms, this lesson lays out a case for multiscale neuroscience data integration.
Difficulty level: Intermediate
Duration: 1:09:33
Speaker: : Sean Hill

This tutorial demonstrates how to perform cell-type deconvolution in order to estimate how proportions of cell-types in the brain change in response to various conditions. While these techniques may be useful in addressing a wide range of scientific questions, this tutorial will focus on the cellular changes associated with major depression (MDD).
Difficulty level: Intermediate
Duration: 1:15:14
Speaker: : Keon Arbabi

This lesson explains the fundamental principles of neuronal communication, such as neuronal spiking, membrane potentials, and cellular excitability, and how these electrophysiological features of the brain may be modelled and simulated digitally.
Difficulty level: Intermediate
Duration: 1:20:42
Speaker: : Etay Hay

This is an in-depth guide on EEG signals and their interaction within brain microcircuits. Participants are also shown techniques and software for simulating, analyzing, and visualizing these signals.
Difficulty level: Intermediate
Duration: 1:30:41
Speaker: : Frank Mazza

Course:
This lesson describes the principles underlying functional magnetic resonance imaging (fMRI), diffusion-weighted imaging (DWI), tractography, and parcellation. These tools and concepts are explained in a broader context of neural connectivity and mental health.
Difficulty level: Intermediate
Duration: 1:47:22
Speaker: : Erin Dickie and John Griffiths