Lesson type
Difficulty level

This lightning talk describes an automated pipline for positron emission tomography (PET) data.
Difficulty level: Intermediate
Duration: 7:27
Speaker: : Soodeh Moallemian
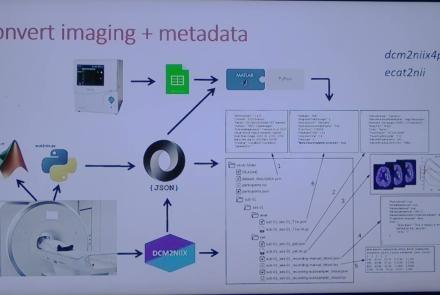
This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 9:23
Speaker: : Cyril Pernet

This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 41:04
Speaker: : Martin Nørgaard
This session dives into practical PET tooling on BIDS data—showing how to run motion correction, register PET↔MRI, extract time–activity curves, and generate standardized PET-BIDS derivatives with clear QC reports. It introduces modular BIDS Apps (head-motion correction, TAC extraction), a full pipeline (PETPrep), and a PET/MRI defacer, with guidance on parameters, outputs, provenance, and why Dockerized containers are the reliable way to run them at scale.
Difficulty level: Intermediate
Duration: 1:05:38
Speaker: : Martin Nørgaard

This session introduces two PET quantification tools—bloodstream for processing arterial blood data and kinfitr for kinetic modeling and quantification—built to work with BIDS/BIDS-derivatives and containers. Bloodstream fuses autosampler and manual measurements (whole blood, plasma, parent fraction) using interpolation or fitted models (incl. hierarchical GAMs) to produce a clean arterial input function (AIF) and whole-blood curves with rich QC reports ready. TAC data (e.g., from PETPrep) and blood (e.g., from bloodstream) can be ingested using kinfitr to run reproducible, GUI-driven analyses: define combined ROIs, calculate weighting factors, estimate blood–tissue delay, choose and chain models (e.g., 2TCM → 1TCM with parameter inheritance), and export parameters/diagnostics. Both are available as Docker apps; workflows emphasize configuration files, reports, and standard outputs to support transparency and reuse.
Difficulty level: Intermediate
Duration: 1:20:56
Speaker: : Granville Matheson

This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz

Course:
This module covers many of the types of non-invasive neurotech and neuroimaging devices including electroencephalography (EEG), electromyography (EMG), electroneurography (ENG), magnetoencephalography (MEG), and more.
Difficulty level: Beginner
Duration: 13:36
Speaker: : Harrison Canning

Course:
This lesson describes the principles underlying functional magnetic resonance imaging (fMRI), diffusion-weighted imaging (DWI), tractography, and parcellation. These tools and concepts are explained in a broader context of neural connectivity and mental health.
Difficulty level: Intermediate
Duration: 1:47:22
Speaker: : Erin Dickie and John Griffiths

Course:
This tutorial introduces pipelines and methods to compute brain connectomes from fMRI data. With corresponding code and repositories, participants can follow along and learn how to programmatically preprocess, curate, and analyze functional and structural brain data to produce connectivity matrices.
Difficulty level: Intermediate
Duration: 1:39:04
Speaker: : Erin Dickie and John Griffiths

In this lesson, you will learn about the connectome, the collective system of neural pathways in an organism, with a closer look at the neurons, synapses, and connections of particular species.
Difficulty level: Intermediate
Duration: 6:48
Speaker: : Marcus Ghosh

This lesson delves into the human nervous system and the immense cellular, connectomic, and functional sophistication therein.
Difficulty level: Intermediate
Duration: 8:41
Speaker: : Marcus Ghosh

In this lesson, you will hear about some of the open issues in the field of neuroscience, as well as a discussion about whether neuroscience works, and how can we know?
Difficulty level: Intermediate
Duration: 6:54
Speaker: : Marcus Ghosh

Course:
The "connectome" is a term, coined in the past decade, that has been used to describe more than one phenomenon in neuroscience. This lecture explains the basics of structural connections at the micro-, meso- and macroscopic scales.
Difficulty level: Beginner
Duration: 1:13:16
Speaker: : Clay Reid

Course:
This talk covers the Human Connectome Project, which aims to provide an unparalleled compilation of neural data, an interface to graphically navigate this data, and the opportunity to achieve never before realized conclusions about the living human brain.
Difficulty level: Advanced
Duration: 59:06
Speaker: : Jennifer Elam

Course:
EyeWire is a game to map the brain. Players are challenged to map branches of a neuron from one side of a cube to the other in a 3D puzzle. Players scroll through the cube and reconstruct neurons with the help of an artificial intelligence algorithm developed at Seung Lab in Princeton University. EyeWire gameplay advances neuroscience by helping researchers discover how neurons connect to process visual information.
Difficulty level: Beginner
Duration: 03:56
Speaker: : EyeWire


Course:
This module explains how neurons come together to create the networks that give rise to our thoughts. The totality of our neurons and their connection is called our connectome. Learn how this connectome changes as we learn, and computes information.
Difficulty level: Beginner
Duration: 7:13
Speaker: : Harrison Canning

This lecture provides an introduction to the application of genetic testing in neurodevelopmental disorders.
Difficulty level: Beginner
Duration: 37:47
Speaker: : Diana-Laura Miclea

This lesson describes the fundamentals of genomics, from central dogma to design and implementation of GWAS, to the computation, analysis, and interpretation of polygenic risk scores.
Difficulty level: Intermediate
Duration: 1:28:16
Speaker: : Dan Felsky

This is a hands-on tutorial on PLINK, the open source whole genome association analysis toolset. The aims of this tutorial are to teach users how to perform basic quality control on genetic datasets, as well as to identify and understand GWAS summary statistics.
Difficulty level: Intermediate
Duration: 1:27:18
Speaker: : Dan Felsky