Lesson type
Difficulty level

This lightning talk describes an automated pipline for positron emission tomography (PET) data.
Difficulty level: Intermediate
Duration: 7:27
Speaker: : Soodeh Moallemian
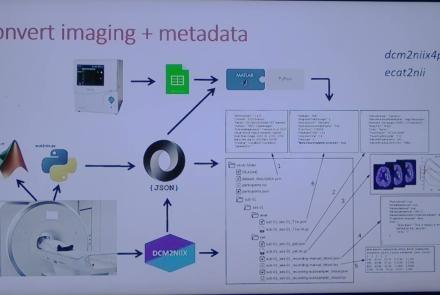
This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 9:23
Speaker: : Cyril Pernet

This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 41:04
Speaker: : Martin Nørgaard
This session dives into practical PET tooling on BIDS data—showing how to run motion correction, register PET↔MRI, extract time–activity curves, and generate standardized PET-BIDS derivatives with clear QC reports. It introduces modular BIDS Apps (head-motion correction, TAC extraction), a full pipeline (PETPrep), and a PET/MRI defacer, with guidance on parameters, outputs, provenance, and why Dockerized containers are the reliable way to run them at scale.
Difficulty level: Intermediate
Duration: 1:05:38
Speaker: : Martin Nørgaard

This session introduces two PET quantification tools—bloodstream for processing arterial blood data and kinfitr for kinetic modeling and quantification—built to work with BIDS/BIDS-derivatives and containers. Bloodstream fuses autosampler and manual measurements (whole blood, plasma, parent fraction) using interpolation or fitted models (incl. hierarchical GAMs) to produce a clean arterial input function (AIF) and whole-blood curves with rich QC reports ready. TAC data (e.g., from PETPrep) and blood (e.g., from bloodstream) can be ingested using kinfitr to run reproducible, GUI-driven analyses: define combined ROIs, calculate weighting factors, estimate blood–tissue delay, choose and chain models (e.g., 2TCM → 1TCM with parameter inheritance), and export parameters/diagnostics. Both are available as Docker apps; workflows emphasize configuration files, reports, and standard outputs to support transparency and reuse.
Difficulty level: Intermediate
Duration: 1:20:56
Speaker: : Granville Matheson

This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz

Course:
This module covers many of the types of non-invasive neurotech and neuroimaging devices including electroencephalography (EEG), electromyography (EMG), electroneurography (ENG), magnetoencephalography (MEG), and more.
Difficulty level: Beginner
Duration: 13:36
Speaker: : Harrison Canning
Course:
This book was written with the goal of introducing researchers and students in a variety of research fields to the intersection of data science and neuroimaging. This book reflects our own experience of doing research at the intersection of data science and neuroimaging and it is based on our experience working with students and collaborators who come from a variety of backgrounds and have a variety of reasons for wanting to use data science approaches in their work. The tools and ideas that we chose to write about are all tools and ideas that we have used in some way in our own research. Many of them are tools that we use on a daily basis in our work. This was important to us for a few reasons: the first is that we want to teach people things that we ourselves find useful. Second, it allowed us to write the book with a focus on solving specific analysis tasks. For example, in many of the chapters you will see that we walk you through ideas while implementing them in code, and with data. We believe that this is a good way to learn about data analysis, because it provides a connecting thread from scientific questions through the data and its representation to implementing specific answers to these questions. Finally, we find these ideas compelling and fruitful. That’s why we were drawn to them in the first place. We hope that our enthusiasm about the ideas and tools described in this book will be infectious enough to convince the readers of their value.
Difficulty level: Intermediate
Duration:
Speaker: :

This talk gives an overview of the Human Brain Project, a 10-year endeavour putting in place a cutting-edge research infrastructure that will allow scientific and industrial researchers to advance our knowledge in the fields of neuroscience, computing, and brain-related medicine.
Difficulty level: Intermediate
Duration: 24:52
Speaker: : Katrin Amunts

This lecture gives an introduction to the European Academy of Neurology, its recent achievements and ambitions.
Difficulty level: Intermediate
Duration: 21:57
Speaker: : Paul Boon

This talk enumerates the challenges regarding data accessibility and reusability inherent in the current scientific publication system, and discusses novel approaches to these challenges, such as the EBRAINS Live Papers platform.
Difficulty level: Beginner
Duration: 18:08
Speaker: : Andrew Davison

This lesson aims to define computational neuroscience in general terms, while providing specific examples of highly successful computational neuroscience projects.
Difficulty level: Beginner
Duration: 59:21
Speaker: : Alla Borisyuk

This lesson covers membrane potential of neurons, and how parameters around this potential have direct consequences on cellular communication at both the individual and population level.
Difficulty level: Beginner
Duration: 28:08
Speaker: : Carl Petersen

In this lesson you will learn about neurons' ability to generate signals called action potentials, and biophysics of voltage-gated ion channels.
Difficulty level: Beginner
Duration: 27:47
Speaker: : Carl Petersen

This lesson discusses voltage-gating kinetics of sodium and potassium channels.
Difficulty level: Beginner
Duration: 19:20
Speaker: : Carl Petersen

In this lesson, you will learn about the ionic basis of the action potential, including the Hodgkin-Huxley model.
Difficulty level: Beginner
Duration: 28:29
Speaker: : Carl Petersen

This lesson delves into the specifics of how action potentials propagate through individual neurons.
Difficulty level: Beginner
Duration: 23:16
Speaker: : Carl Petersen

This lesson discusses long-range inhibitory connections in the brain, with examples from three different systems.
Difficulty level: Beginner
Duration: 19:05
Speaker: : Carl Petersen

Course:
An introduction to data management, manipulation, visualization, and analysis for neuroscience. Students will learn scientific programming in Python, and use this to work with example data from areas such as cognitive-behavioral research, single-cell recording, EEG, and structural and functional MRI. Basic signal processing techniques including filtering are covered. The course includes a Jupyter Notebook and video tutorials.
Difficulty level: Beginner
Duration: 1:09:16
Speaker: : Aaron J. Newman