Lesson type
Difficulty level

This lightning talk describes an automated pipline for positron emission tomography (PET) data.
Difficulty level: Intermediate
Duration: 7:27
Speaker: : Soodeh Moallemian
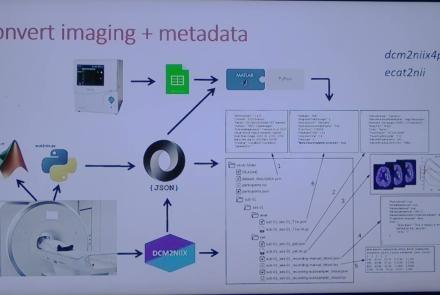
This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 9:23
Speaker: : Cyril Pernet

This session introduces the PET-to-BIDS (PET2BIDS) library, a toolkit designed to simplify the conversion and preparation of PET imaging datasets into BIDS-compliant formats. It supports multiple data types and formats (e.g., DICOM, ECAT7+, nifti, JSON), integrates seamlessly with Excel-based metadata, and provides automated routines for metadata updates, blood data conversion, and JSON synchronization. PET2BIDS improves human readability by mapping complex reconstruction names into standardized, descriptive labels and offers extensive documentation, examples, and video tutorials to make adoption easier for researchers.
Difficulty level: Intermediate
Duration: 41:04
Speaker: : Martin Nørgaard
This session dives into practical PET tooling on BIDS data—showing how to run motion correction, register PET↔MRI, extract time–activity curves, and generate standardized PET-BIDS derivatives with clear QC reports. It introduces modular BIDS Apps (head-motion correction, TAC extraction), a full pipeline (PETPrep), and a PET/MRI defacer, with guidance on parameters, outputs, provenance, and why Dockerized containers are the reliable way to run them at scale.
Difficulty level: Intermediate
Duration: 1:05:38
Speaker: : Martin Nørgaard

This session introduces two PET quantification tools—bloodstream for processing arterial blood data and kinfitr for kinetic modeling and quantification—built to work with BIDS/BIDS-derivatives and containers. Bloodstream fuses autosampler and manual measurements (whole blood, plasma, parent fraction) using interpolation or fitted models (incl. hierarchical GAMs) to produce a clean arterial input function (AIF) and whole-blood curves with rich QC reports ready. TAC data (e.g., from PETPrep) and blood (e.g., from bloodstream) can be ingested using kinfitr to run reproducible, GUI-driven analyses: define combined ROIs, calculate weighting factors, estimate blood–tissue delay, choose and chain models (e.g., 2TCM → 1TCM with parameter inheritance), and export parameters/diagnostics. Both are available as Docker apps; workflows emphasize configuration files, reports, and standard outputs to support transparency and reuse.
Difficulty level: Intermediate
Duration: 1:20:56
Speaker: : Granville Matheson

This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz

Course:
This module covers many of the types of non-invasive neurotech and neuroimaging devices including electroencephalography (EEG), electromyography (EMG), electroneurography (ENG), magnetoencephalography (MEG), and more.
Difficulty level: Beginner
Duration: 13:36
Speaker: : Harrison Canning

Course:
This lesson gives an introduction to the Mathematics chapter of Datalabcc's Foundations in Data Science series.
Difficulty level: Beginner
Duration: 2:53
Speaker: : Barton Poulson

Course:
This lesson serves a primer on elementary algebra.
Difficulty level: Beginner
Duration: 3:03
Speaker: : Barton Poulson

Course:
This lesson provides a primer on linear algebra, aiming to demonstrate how such operations are fundamental to many data science.
Difficulty level: Beginner
Duration: 5:38
Speaker: : Barton Poulson

Course:
In this lesson, users will learn about linear equation systems, as well as follow along some practical use cases.
Difficulty level: Beginner
Duration: 5:24
Speaker: : Barton Poulson

Course:
This talk gives a primer on calculus, emphasizing its role in data science.
Difficulty level: Beginner
Duration: 4:17
Speaker: : Barton Poulson

Course:
This lesson clarifies how calculus relates to optimization in a data science context.
Difficulty level: Beginner
Duration: 8:43
Speaker: : Barton Poulson

Course:
This lesson covers Big O notation, a mathematical notation that describes the limiting behavior of a function as it tends towards a certain value or infinity, proving useful for data scientists who want to evaluate their algorithms' efficiency.
Difficulty level: Beginner
Duration: 5:19
Speaker: : Barton Poulson

Course:
This lesson serves as a primer on the fundamental concepts underlying probability.
Difficulty level: Beginner
Duration: 7:33
Speaker: : Barton Poulson

Serving as good refresher, this lesson explains the maths and logic concepts that are important for programmers to understand, including sets, propositional logic, conditional statements, and more.
This compilation is courtesy of freeCodeCamp.
Difficulty level: Beginner
Duration: 1:00:07
Speaker: : Shawn Grooms

This lesson provides a useful refresher which will facilitate the use of Matlab, Octave, and various matrix-manipulation and machine-learning software.
This lesson was created by RootMath.
Difficulty level: Beginner
Duration: 1:21:30
Speaker: :

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman

This lesson describes a definitional framework for fairness and health equity in the age of the algorithm. While acknowledging the impressive capability of machine learning to positively affect health equity, this talk outlines potential (and actual) pitfalls which come with such powerful tools, ultimately making the case for collaborative, interdisciplinary, and transparent science as a way to operationalize fairness in health equity.
Difficulty level: Beginner
Duration: 1:06:35
Speaker: : Laura Sikstrom

This lesson is the first part of a three-part series on the development of neuroinformatic infrastructure to ensure compliance with European data privacy standards and laws.
Difficulty level: Beginner
Duration: 1:10:05
Speaker: : Michael Schirner