Lesson type
Difficulty level

In this lesson you will learn about current efforts towards integrating multimodal human brain data using the open source SCORE HED library schema.
Difficulty level: Beginner
Duration: 23:29
Speaker: : Dora Hermes

This talk covers the differences between applying HED annotation to fMRI datasets versus other neuroimaging practices, and also introduces an analysis pipeline using HED tags.
Difficulty level: Beginner
Duration: 22:52
Speaker: : Monique Denissen

This lecture discusses the FAIR principles as they apply to electrophysiology data and metadata, the building blocks for community tools and standards, platforms and grassroots initiatives, and the challenges therein.
Difficulty level: Beginner
Duration: 8:11
Speaker: : Thomas Wachtler
This lecture contains an overview of electrophysiology data reuse within the EBRAINS ecosystem.
Difficulty level: Beginner
Duration: 15:57
Speaker: : Andrew Davison

This video explains what metadata is, why it is important, and how you can organize your metadata to increase the FAIRness of your data on EBRAINS.
Difficulty level: Beginner
Duration: 17:23
Speaker: : Ulrike Schlegel

Course:
This lesson gives an introduction to the Mathematics chapter of Datalabcc's Foundations in Data Science series.
Difficulty level: Beginner
Duration: 2:53
Speaker: : Barton Poulson

Course:
This lesson serves a primer on elementary algebra.
Difficulty level: Beginner
Duration: 3:03
Speaker: : Barton Poulson

Course:
This lesson provides a primer on linear algebra, aiming to demonstrate how such operations are fundamental to many data science.
Difficulty level: Beginner
Duration: 5:38
Speaker: : Barton Poulson

Course:
In this lesson, users will learn about linear equation systems, as well as follow along some practical use cases.
Difficulty level: Beginner
Duration: 5:24
Speaker: : Barton Poulson

Course:
This talk gives a primer on calculus, emphasizing its role in data science.
Difficulty level: Beginner
Duration: 4:17
Speaker: : Barton Poulson

Course:
This lesson clarifies how calculus relates to optimization in a data science context.
Difficulty level: Beginner
Duration: 8:43
Speaker: : Barton Poulson

Course:
This lesson covers Big O notation, a mathematical notation that describes the limiting behavior of a function as it tends towards a certain value or infinity, proving useful for data scientists who want to evaluate their algorithms' efficiency.
Difficulty level: Beginner
Duration: 5:19
Speaker: : Barton Poulson

Course:
This lesson serves as a primer on the fundamental concepts underlying probability.
Difficulty level: Beginner
Duration: 7:33
Speaker: : Barton Poulson

Serving as good refresher, this lesson explains the maths and logic concepts that are important for programmers to understand, including sets, propositional logic, conditional statements, and more.
This compilation is courtesy of freeCodeCamp.
Difficulty level: Beginner
Duration: 1:00:07
Speaker: : Shawn Grooms

This lesson provides a useful refresher which will facilitate the use of Matlab, Octave, and various matrix-manipulation and machine-learning software.
This lesson was created by RootMath.
Difficulty level: Beginner
Duration: 1:21:30
Speaker: :

In this session the Medical Informatics Platform (MIP) federated analytics is presented. The current and future analytical tools implemented in the MIP will be detailed along with the constructs, tools, processes, and restrictions that formulate the solution provided. MIP is a platform providing advanced federated analytics for diagnosis and research in clinical neuroscience research. It is targeting clinicians, clinical scientists and clinical data scientists. It is designed to help adopt advanced analytics, explore harmonized medical data of neuroimaging, neurophysiological and medical records as well as research cohort datasets, without transferring original clinical data. It can be perceived as a virtual database that seamlessly presents aggregated data from distributed sources, provides access and analyze imaging and clinical data, securely stored in hospitals, research archives and public databases. It leverages and re-uses decentralized patient data and research cohort datasets, without transferring original data. Integrated statistical analysis tools and machine learning algorithms are exposed over harmonized, federated medical data.
Difficulty level: Intermediate
Duration: 15:05
Speaker: : Giorgos Papanikos

The Medical Informatics Platform (MIP) is a platform providing federated analytics for diagnosis and research in clinical neuroscience research. The federated analytics is possible thanks to a distributed engine that executes computations and transfers information between the members of the federation (hospital nodes). In this talk the speaker will describe the process of designing and implementing new analytical tools, i.e. statistical and machine learning algorithms. Mr. Sakellariou will further describe the environment in which these federated algorithms run, the challenges and the available tools, the principles that guide its design and the followed general methodology for each new algorithm. One of the most important challenges which are faced is to design these tools in a way that does not compromise the privacy of the clinical data involved. The speaker will show how to address the main questions when designing such algorithms: how to decompose and distribute the computations and what kind of information to exchange between nodes, in order to comply with the privacy constraint mentioned above. Finally, also the subject of validating these federated algorithms will be briefly touched.
Difficulty level: Intermediate
Duration: 20:26
Speaker: : Jason Skellariou

The Medical Informatics Platform (MIP) Dementia had been installed in several memory clinics across Europe allowing them to federate their real-world databases. Research open access databases had also been integrated such as ADNI (Alzheimer’s Dementia Neuroimaging Initiative), reaching a cumulative case load of more than 5,000 patients (major cognitive disorder due to Alzheimer’s disease, other major cognitive disorder, minor cognitive disorder, controls). The statistic and machine learning tools implemented in the MIP allowed researchers to conduct easily federated analyses among Italian memory clinics (Redolfi et al. 2020) and also across borders between the French (Lille), the Swiss (Lausanne) and the Italian (Brescia) datasets.
Difficulty level: Intermediate
Duration: 16:44
Speaker: : Mélanie Leroy
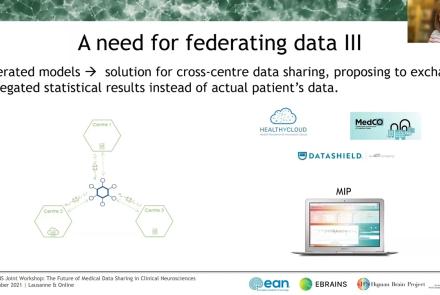
This talks presents ethics requirements of the Medical Informatics Platform, a data sharing platform for medical data using data federation mechanisms. The talk presents how the Medical Informatics Platform (MIP) works and which ethical requirements need to be considered when working with federated data.
Difficulty level: Intermediate
Duration: 16:25
Speaker: : Erika Borcel