Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

In this hands-on session, you will learn how to explore and work with DataLad datasets, containers, and structures using Jupyter notebooks.
Difficulty level: Beginner
Duration: 58:05
Speaker: : Michał Szczepanik

In this tutorial, you will learn how to use TVB-NEST toolbox on your local computer.
Difficulty level: Beginner
Duration: 2:16
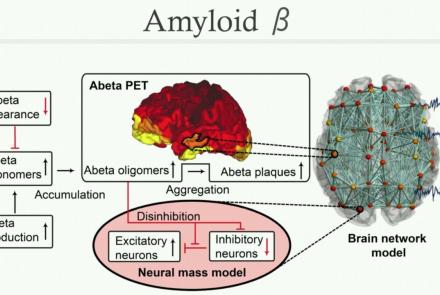
This tutorial provides instruction on how to perform multi-scale simulation of Alzheimer's disease on The Virtual Brain Simulation Platform.
Difficulty level: Beginner
Duration: 29:08

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

Course:
An introduction to data management, manipulation, visualization, and analysis for neuroscience. Students will learn scientific programming in Python, and use this to work with example data from areas such as cognitive-behavioral research, single-cell recording, EEG, and structural and functional MRI. Basic signal processing techniques including filtering are covered. The course includes a Jupyter Notebook and video tutorials.
Difficulty level: Beginner
Duration: 1:09:16
Speaker: : Aaron J. Newman

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This lesson provides a hands-on tutorial for generating simulated brain data within the EBRAINS ecosystem.
Difficulty level: Beginner
Duration: 32:58
Speaker: : Jil Meier