Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This is a tutorial on designing a Bayesian inference model to map belief trajectories, with emphasis on gaining familiarity with Hierarchical Gaussian Filters (HGFs).
This lesson corresponds to slides 65-90 of the PDF below.
Difficulty level: Intermediate
Duration: 1:15:04
Speaker: : Daniel Hauke

This lesson introduces the practical exercises which accompany the previous lessons on animal and human connectomes in the brain and nervous system.
Difficulty level: Intermediate
Duration: 4:10
Speaker: : Dan Goodman
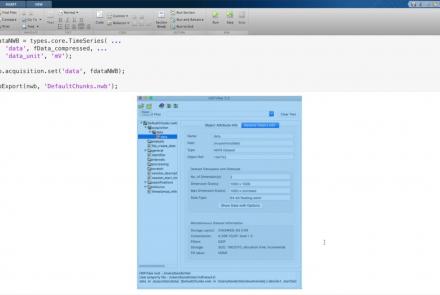
This lesson provides a tutorial on how to handle writing very large data in MatNWB.
Difficulty level: Advanced
Duration: 16:18
Speaker: : Ben Dichter

This lesson provides an overview of the CaImAn package, as well as a demonstration of usage with NWB.
Difficulty level: Intermediate
Duration: 44:37
Speaker: : Andrea Giovannucci

This lesson gives an overview of the SpikeInterface package, including demonstration of data loading, preprocessing, spike sorting, and comparison of spike sorters.
Difficulty level: Intermediate
Duration: 1:10:28
Speaker: : Alessio Buccino

In this lesson, users will learn about the NWBWidgets package, including coverage of different data types, and information for building custom widgets within this framework.
Difficulty level: Intermediate
Duration: 47:15
Speaker: : Ben Dichter