Lesson type
Difficulty level

Course:
This session provides users with an introduction to tools and resources that facilitate the implementation of FAIR in their research.
Difficulty level: Beginner
Duration: 38:36

This video gives a short introduction to the EBRAINS data sharing platform, why it was developed, and how it contributes to open data sharing.
Difficulty level: Beginner
Duration: 17:32
Speaker: : Ida Aasebø

This video explains what metadata is, why it is important, and how you can organize your metadata to increase the FAIRness of your data on EBRAINS.
Difficulty level: Beginner
Duration: 17:23
Speaker: : Ulrike Schlegel

This video introduces the importance of writing a Data Descriptor to accompany your dataset on EBRAINS. It gives concrete examples on what information to include and highlights how this makes your data more FAIR.
Difficulty level: Beginner
Duration: 9:48
Speaker: : Ingrid Reiten

Course:
KnowledgeSpace (KS) is a data discoverability portal and neuroscience encyclopedia that was developed to make it easier for the neuroscience community to find publicly available datasets that adhere to the FAIR Principles and to provide an integrated view of neuroscience concepts found in Wikipedia and NeuroLex linked with PubMed and 17 of the world's leading neuroscience repositories. In short, KS provides a single point of entry where reseaerchers can search for a neuroscience concept of interest and receive results that include: i. a description of the term found in Wikipedia/NeuroLex, ii. links to publicly available datasets related to the concept of interest, and iii. up-to-date references that support the concept of interests found in PubMed. APIs are available so that developers of other neuroscience research infrastructures can integrate KS components in their infrastructures. If your repository or your favorite repository is not indexed in KS, please contact us.
Difficulty level: Beginner
Duration: 6:14
Speaker: : Heather Topple

In this lesson, users will learn about the importance of proper citation of software resources and tools used in neuroscientific research.
Difficulty level: Beginner
Duration: 58:00
Speaker: : Neil Chue Hong & Daniel Katz

Since their introduction in 2016, the FAIR data principles have gained increasing recognition and adoption in global neuroscience. FAIR defines a set of high level principles and practices for making digital objects, including data, software and workflows, Findable, Accessible, Interoperable and Reusable. But FAIR is not a specification; it leaves many of the specifics up to individual scientific disciplines to define. INCF has been leading the way in promoting, defining and implementing FAIR data practices for neuroscience. We have been bringing together researchers, infrastructure providers, industry and publishers through our programs and networks.
Difficulty level: Beginner
Duration: 1:28

This lesson provides an introduction to the lifecycle of EEG/ERP data, describing the various phases through which these data pass, from collection to publication.
Difficulty level: Beginner
Duration: 35:30
Speaker: : Kateřina Vařeková

In this lesson you will learn about experimental design for EEG acquisition, as well as the first phases of the EEG/ERP data lifecycle.
Difficulty level: Beginner
Duration: 30:04
Speaker: : Kateřina Vařeková

This lesson provides an overview of the current regulatory measures in place regarding experimental data security and privacy.
Difficulty level: Beginner
Duration: 31:00
Speaker: : Kateřina Vařeková

In this lesson, you will learn the appropriate methods for collection of both data and associated metadata during EEG experiments.
Difficulty level: Beginner
Duration: 29:14
Speaker: : Kateřina Vařeková

This lesson goes over methods for managing EEG/ERP data after it has been collected, from annotation to publication.
Difficulty level: Beginner
Duration: 39:25
Speaker: : Kateřina Vařeková

In this final lesson of the course, you will learn broadly about EEG signal processing, as well as specific applications which make this kind of brain signal valuable to researchers and clinicians.
Difficulty level: Beginner
Duration: 34:51
Speaker: : Kateřina Vařeková

Course:
This lesson introduces the EEGLAB toolbox, as well as motivations for its use.
Difficulty level: Beginner
Duration: 15:32
Speaker: : Arnaud Delorme
Course:
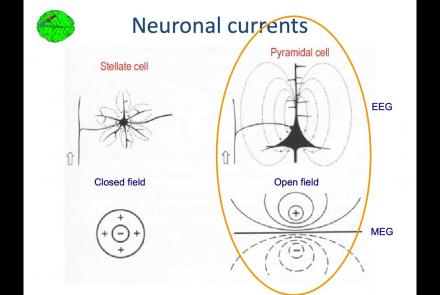
In this lesson, you will learn about the biological activity which generates and is measured by the EEG signal.
Difficulty level: Beginner
Duration: 6:53
Speaker: : Arnaud Delorme

Course:
This lesson goes over the characteristics of EEG signals when analyzed in source space (as opposed to sensor space).
Difficulty level: Beginner
Duration: 10:56
Speaker: : Arnaud Delorme

Course:
This lesson describes the development of EEGLAB as well as to what extent it is used by the research community.
Difficulty level: Beginner
Duration: 6:06
Speaker: : Arnaud Delorme

Course:
This lesson provides instruction as to how to build a processing pipeline in EEGLAB for a single participant.
Difficulty level: Beginner
Duration: 9:20
Speaker: :

Course:
Whereas the previous lesson of this course outlined how to build a processing pipeline for a single participant, this lesson discusses analysis pipelines for multiple participants simultaneously.
Difficulty level: Beginner
Duration: 10:55
Speaker: : Arnaud Delorme

Course:
In addition to outlining the motivations behind preprocessing EEG data in general, this lesson covers the first step in preprocessing data with EEGLAB, importing raw data.
Difficulty level: Beginner
Duration: 8:30
Speaker: : Arnaud Delorme