Lesson type
Difficulty level

This lesson provides an overview of self-supervision as it relates to neural data tasks and the Mine Your Own vieW (MYOW) approach.
Difficulty level: Beginner
Duration: 25:50
Speaker: : Eva Dyer

Course:
This lesson provides a conceptual overview of the rudiments of machine learning, including its bases in traditional statistics and the types of questions it might be applied to. The lesson was presented in the context of the BrainHack School 2020.
Difficulty level: Beginner
Duration: 01:22:18
Speaker: : Estefany Suárez

Course:
This lesson provides a hands-on, Jupyter-notebook-based tutorial to apply machine learning in Python to brain-imaging data.
Difficulty level: Beginner
Duration: 02:13:53
Speaker: : Jake Vogel

Course:
This lesson presents advanced machine learning algorithms for neuroimaging, while addressing some real-world considerations related to data size and type.
Difficulty level: Beginner
Duration: 01:17:14
Speaker: : Gael Varoquaux

Course:
This lesson from freeCodeCamp introduces Scikit-learn, the most widely used machine learning Python library.
Difficulty level: Beginner
Duration: 02:09:22
Speaker: :

Course:
This lecture covers FAIR atlases, including their background and construction, as well as how they can be created in line with the FAIR principles.
Difficulty level: Beginner
Duration: 14:24
Speaker: : Heidi Kleven

Course:
The state of the field regarding the diagnosis and treatment of major depressive disorder (MDD) is discussed. Current challenges and opportunities facing the research and clinical communities are outlined, including appropriate quantitative and qualitative analyses of the heterogeneity of biological, social, and psychiatric factors which may contribute to MDD.
Difficulty level: Beginner
Duration: 1:29:28
Speaker: : Brett Jones, Victor Tang

Course:
This lesson delves into the opportunities and challenges of telepsychiatry. While novel digital approaches to clinical research and care have the potential to improve and accelerate patient outcomes, researchers and care providers must consider new population factors, such as digital disparity.
Difficulty level: Beginner
Duration: 1:20:28
Speaker: : Abhi Pratap
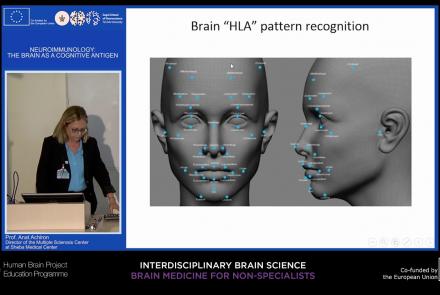
This lecture focuses on how the immune system can target and attack the nervous system to produce autoimmune responses that may result in diseases such as multiple sclerosis, neuromyelitis, and lupus cerebritis manifested by motor, sensory, and cognitive impairments. Despite the fact that the brain is an immune-privileged site, autoreactive lymphocytes producing proinflammatory cytokines can cause active brain inflammation, leading to myelin and axonal loss.
Difficulty level: Beginner
Duration: 37:36
Speaker: : Anat Achiron
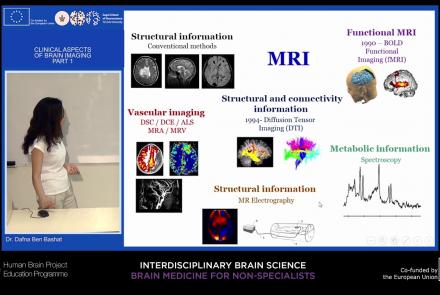
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat
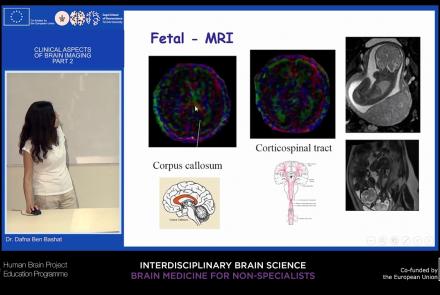
This lecture picks up from the previous lesson, providing an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 41:00
Speaker: : Dafna Ben Bashat

This lesson discusses both state-of-the-art detection and prevention schema in working with neurodegenerative diseases.
Difficulty level: Beginner
Duration: 1:02:29
Speaker: : Nir Giladi

This lecture provides an overview of depression (epidemiology and course of the disorder), clinical presentation, somatic co-morbidity, and treatment options.
Difficulty level: Beginner
Duration: 37:51
Speaker: : Barbara Sperner-Unterweger

In this lesson, you will learn about how genetics can contribute to our understanding of psychiatric phenotypes.
Difficulty level: Beginner
Duration: 55:15
Speaker: : Sven Cichon

This lecture focuses on the rationale for employing neuroimaging methods for movement disorders.
Difficulty level: Beginner
Duration: 1:04:04
Speaker: : Bogdan Draganski

This lecture provides an overview of some of the essential concepts in neuropharmacology (e.g. receptor binding, agonism, antagonism), an introduction to pharmacodynamics and pharmacokinetics, and an overview of the drug discovery process relative to diseases of the central nervous system.
Difficulty level: Beginner
Duration: 45:47
Speaker: : Sandra Santos-Sierra

This lesson provides an overview of how to construct computational pipelines for neurophysiological data using DataJoint.
Difficulty level: Beginner
Duration: 17:37
Speaker: : Dimitri Yatsenko

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

In this hands-on session, you will learn how to explore and work with DataLad datasets, containers, and structures using Jupyter notebooks.
Difficulty level: Beginner
Duration: 58:05
Speaker: : Michał Szczepanik