Lesson type
Difficulty level

Course:
In this tutorial on simulating whole-brain activity using Python, participants can follow along using corresponding code and repositories, learning the basics of neural oscillatory dynamics, evoked responses and EEG signals, ultimately leading to the design of a network model of whole-brain anatomical connectivity.
Difficulty level: Intermediate
Duration: 1:16:10
Speaker: : John Griffiths

This lecture goes into detailed description of how to process workflows in the virtual research environment (VRE), including approaches for standardization, metadata, containerization, and constructing and maintaining scientific pipelines.
Difficulty level: Intermediate
Duration: 1:03:55
Speaker: : Patrik Bey

This lesson introduces some practical exercises which accompany the Synapses and Networks portion of this Neuroscience for Machine Learners course.
Difficulty level: Intermediate
Duration: 3:51
Speaker: : Dan Goodman

This tutorial provides instruction on how to simulate brain tumors with TVB (reproducing publication: Marinazzo et al. 2020 Neuroimage). This tutorial comprises a didactic video, jupyter notebooks, and full data set for the construction of virtual brains from patients and health controls.
Difficulty level: Intermediate
Duration: 10:01

The tutorial on modelling strokes in TVB includes a didactic video and jupyter notebooks (reproducing publication: Falcon et al. 2016 eNeuro).
Difficulty level: Intermediate
Duration: 7:43

Course:
This lecture and tutorial focuses on measuring human functional brain networks, as well as how to account for inherent variability within those networks.
Difficulty level: Intermediate
Duration: 50:44
Speaker: : Caterina Gratton

Course:
This lesson gives an introduction to the central concepts of machine learning, and how they can be applied in Python using the scikit-learn package.
Difficulty level: Intermediate
Duration: 2:22:28
Speaker: : Jake Vanderplas

Course:
This lecture introduces you to the basics of the Amazon Web Services public cloud. It covers the fundamentals of cloud computing and goes through both the motivations and processes involved in moving your research computing to the cloud.
Difficulty level: Intermediate
Duration: 3:09:12
Speaker: : Amanda Tan & Ariel Rokem
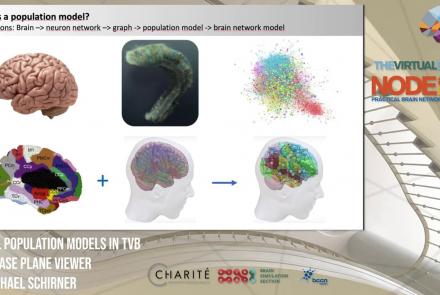
This lesson introduces population models and the phase plane, and is part of the The Virtual Brain (TVB) Node 10 Series, a 4-day workshop dedicated to learning about the full brain simulation platform TVB, as well as brain imaging, brain simulation, personalised brain models, and TVB use cases.
Difficulty level: Intermediate
Duration: 1:10:41
Speaker: : Michael Schirner

In this tutorial, you will learn how to run a typical TVB simulation.
Difficulty level: Intermediate
Duration: 1:29:13
Speaker: : Paul Triebkorn

This lesson introduces TVB-multi-scale extensions and other TVB tools which facilitate modeling and analyses of multi-scale data.
Difficulty level: Intermediate
Duration: 36:10
Speaker: : Dionysios Perdikis

This tutorial introduces The Virtual Mouse Brain (TVMB), walking users through the necessary steps for performing simulation operations on animal brain data.
Difficulty level: Intermediate
Duration: 42:43
Speaker: : Patrik Bey

In this tutorial, you will learn the necessary steps in modeling the brain of one of the most commonly studied animals among non-human primates, the macaque.
Difficulty level: Intermediate
Duration: 1:00:08
Speaker: : Julie Courtiol
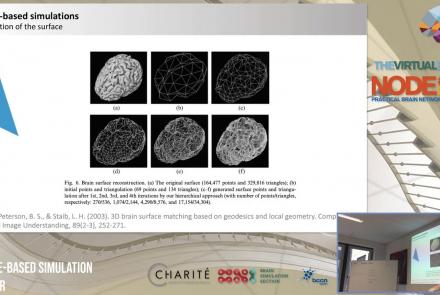
This lecture delves into cortical (i.e., surface-based) brain simulations, as well as subcortical (i.e., deep brain) stimulations, covering the definitions, motivations, and implementations of both.
Difficulty level: Intermediate
Duration: 39:05
Speaker: : Jil Meier

This lecture provides an introduction to entropy in general, and multi-scale entropy (MSE) in particular, highlighting the potential clinical applications of the latter.
Difficulty level: Intermediate
Duration: 39:05
Speaker: : Jil Meier

This lecture gives an overview of how to prepare and preprocess neuroimaging (EEG/MEG) data for use in TVB.
Difficulty level: Intermediate
Duration: 1:40:52
Speaker: : Paul Triebkorn

In this lecture, you will learn about various neuroinformatic resources which allow for 3D reconstruction of brain models.
Difficulty level: Intermediate
Duration: 1:36:57
Speaker: : Michael Schirner

This lecture provides an general introduction to epilepsy, as well as why and how TVB can prove useful in building and testing epileptic models.
Difficulty level: Intermediate
Duration: 37:12
Speaker: : Julie Courtiol

Course:
This lecture covers the rationale for developing the DAQCORD, a framework for the design, documentation, and reporting of data curation methods in order to advance the scientific rigour, reproducibility, and analysis of data.
Difficulty level: Intermediate
Duration: 17:08
Speaker: : Ari Ercole

In this session the Medical Informatics Platform (MIP) federated analytics is presented. The current and future analytical tools implemented in the MIP will be detailed along with the constructs, tools, processes, and restrictions that formulate the solution provided. MIP is a platform providing advanced federated analytics for diagnosis and research in clinical neuroscience research. It is targeting clinicians, clinical scientists and clinical data scientists. It is designed to help adopt advanced analytics, explore harmonized medical data of neuroimaging, neurophysiological and medical records as well as research cohort datasets, without transferring original clinical data. It can be perceived as a virtual database that seamlessly presents aggregated data from distributed sources, provides access and analyze imaging and clinical data, securely stored in hospitals, research archives and public databases. It leverages and re-uses decentralized patient data and research cohort datasets, without transferring original data. Integrated statistical analysis tools and machine learning algorithms are exposed over harmonized, federated medical data.
Difficulty level: Intermediate
Duration: 15:05
Speaker: : Giorgos Papanikos