Lesson type
Difficulty level

This lecture describes how to build research workflows, including a demonstrate using DataJoint Elements to build data pipelines.
Difficulty level: Intermediate
Duration: 47:00
Speaker: : Dimitri Yatsenko

This lesson provides an introduction to the Symposium on Science Management at the Canadian Association for Neuroscience 2019 Meeting.
Difficulty level: Beginner
Duration: 9:52
Speaker: : Randy McIntosh

This lesson gives a primer to project management in a scientific context, with a particular neuroinformatic case study.
Difficulty level: Beginner
Duration: 19:06
Speaker: : Kelly Shen

In this lesson, you will hear about the current challenges regarding data management, as well as policies and resources aimed to address them.
Difficulty level: Beginner
Duration: 18:13
Speaker: : Mojib Javadi

This lesson covers "Knowledge Translation", the activities involved in moving research from the laboratory, the research journal, and the academic conference into the hands of people and organizations who can put it to practical use.
Difficulty level: Beginner
Duration: 15:05
Speaker: : Jordan Antflick

In this lesson, you will hear about the various methods developed and employed in managing performance.
Difficulty level: Beginner
Duration: 12:57
Speaker: : Christa Studzinski

This lesson provides an overview of how to manage relationships in a research context, while highlighting the need for effective communication at various levels.
Difficulty level: Beginner
Duration:
Speaker: : Helena Ledmyr

This lecture covers a wide range of aspects regarding neuroinformatics and data governance, describing both their historical developments and current trajectories. Particular tools, platforms, and standards to make your research more FAIR are also discussed.
Difficulty level: Beginner
Duration: 54:58
Speaker: : Franco Pestilli

Course:
This lecture introduces you to the basics of the Amazon Web Services public cloud. It covers the fundamentals of cloud computing and goes through both the motivations and processes involved in moving your research computing to the cloud.
Difficulty level: Intermediate
Duration: 3:09:12
Speaker: : Amanda Tan & Ariel Rokem

This lecture discusses how FAIR practices affect personalized data models, including workflows, challenges, and how to improve these practices.
Difficulty level: Beginner
Duration: 13:16
Speaker: : Kelly Shen

In this talk, you will learn how brainlife.io works, and how it can be applied to neuroscience data.
Difficulty level: Beginner
Duration: 10:14
Speaker: : Franco Pestilli

Course:
As a part of NeuroHackademy 2020, this lecture delves into cloud computing, focusing on Amazon Web Services.
Difficulty level: Beginner
Duration: 01:43:59
Speaker: : Tara Madhyastha, Andrew Crabb, Ariel Rokem

Course:
This talk presents an overview of CBRAIN, a web-based platform that allows neuroscientists to perform computationally intensive data analyses by connecting them to high-performance computing facilities across Canada and around the world.
Difficulty level: Beginner
Duration: 56:07
Speaker: : Shawn Brown

This lesson gives a description of the BrainHealth Databank, a repository of many types of health-related data, whose aim is to accelerate research, improve care, and to help better understand and diagnose mental illness, as well as develop new treatments and prevention strategies.
This lesson corresponds to slides 46-78 of the PDF below.
Difficulty level: Beginner
Duration: 1:12:25
Speaker: : Joanna Yu
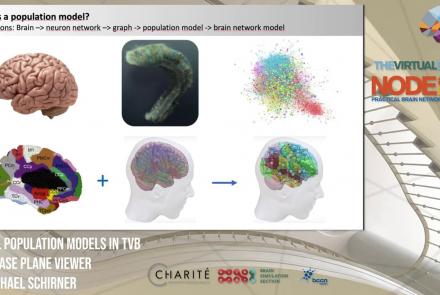
This lesson introduces population models and the phase plane, and is part of the The Virtual Brain (TVB) Node 10 Series, a 4-day workshop dedicated to learning about the full brain simulation platform TVB, as well as brain imaging, brain simulation, personalised brain models, and TVB use cases.
Difficulty level: Intermediate
Duration: 1:10:41
Speaker: : Michael Schirner

This lesson introduces TVB-multi-scale extensions and other TVB tools which facilitate modeling and analyses of multi-scale data.
Difficulty level: Intermediate
Duration: 36:10
Speaker: : Dionysios Perdikis
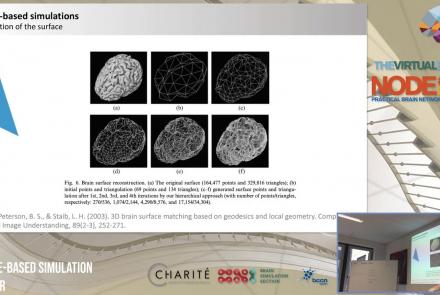
This lecture delves into cortical (i.e., surface-based) brain simulations, as well as subcortical (i.e., deep brain) stimulations, covering the definitions, motivations, and implementations of both.
Difficulty level: Intermediate
Duration: 39:05
Speaker: : Jil Meier

This lecture provides an introduction to entropy in general, and multi-scale entropy (MSE) in particular, highlighting the potential clinical applications of the latter.
Difficulty level: Intermediate
Duration: 39:05
Speaker: : Jil Meier

This lecture gives an overview of how to prepare and preprocess neuroimaging (EEG/MEG) data for use in TVB.
Difficulty level: Intermediate
Duration: 1:40:52
Speaker: : Paul Triebkorn

In this lecture, you will learn about various neuroinformatic resources which allow for 3D reconstruction of brain models.
Difficulty level: Intermediate
Duration: 1:36:57
Speaker: : Michael Schirner