Lesson type
Difficulty level

Course:
This lesson gives an introduction to high-performance computing with the Compute Canada network, first providing an overview of use cases for HPC and then a hands-on tutorial. Though some examples might seem specific to the Calcul Québec, all computing clusters in the Compute Canada network share the same software modules and environments.
Difficulty level: Beginner
Duration: 02:49:34
Speaker: : Félix-Antoine Fortin

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

Course:
This lesson describes the principles underlying functional magnetic resonance imaging (fMRI), diffusion-weighted imaging (DWI), tractography, and parcellation. These tools and concepts are explained in a broader context of neural connectivity and mental health.
Difficulty level: Intermediate
Duration: 1:47:22
Speaker: : Erin Dickie and John Griffiths

This lesson explores how researchers try to understand neural networks, particularly in the case of observing neural activity.
Difficulty level: Intermediate
Duration: 8:20
Speaker: : Marcus Ghosh
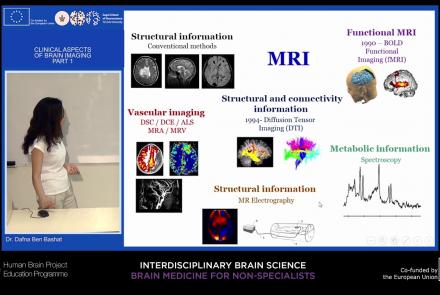
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

This lecture provides an introduction to the Brain Imaging Data Structure (BIDS), a standard for organizing human neuroimaging datasets.
Difficulty level: Intermediate
Duration: 56:49
Speaker: : Chris Gorgolewski

Course:
This lecture presents an overview of functional brain parcellations, as well as a set of tutorials on bootstrap agregation of stable clusters (BASC) for fMRI brain parcellation.
Difficulty level: Advanced
Duration: 50:28
Speaker: : Pierre Bellec

Course:
This lecture covers the needs and challenges involved in creating a FAIR ecosystem for neuroimaging research.
Difficulty level: Beginner
Duration: 12:26
Speaker: : Camille Maumet

This lecture covers the NIDM data format within BIDS to make your datasets more searchable, and how to optimize your dataset searches.
Difficulty level: Beginner
Duration: 12:33
Speaker: : David Keator
This lecture covers the processes, benefits, and challenges involved in designing, collecting, and sharing FAIR neuroscience datasets.
Difficulty level: Beginner
Duration: 11:35
Speaker: : Julie Boyle & Valentina Borghesani
This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz
This lecture covers the benefits and difficulties involved when re-using open datasets, and how metadata is important to the process.
Difficulty level: Beginner
Duration: 11:20
Speaker: : Elizabeth DuPre
This lecture provides guidance on the ethical considerations the clinical neuroimaging community faces when applying the FAIR principles to their research.
Difficulty level: Beginner
Duration: 13:11
Speaker: : Gustav Nilsonne

This lecture covers the history of behaviorism and the ultimate challenge to behaviorism.
Difficulty level: Beginner
Duration: 1:19:08
Speaker: : Paul F.M.J. Verschure

This lecture covers various learning theories.
Difficulty level: Beginner
Duration: 1:00:42
Speaker: : Paul F.M.J. Verschure

This lesson characterizes different types of learning in a neuroscientific and cellular context, and various models employed by researchers to investigate the mechanisms involved.
Difficulty level: Intermediate
Duration: 3:54
Speaker: : Dan Goodman

In this lesson, you will learn about different approaches to modeling learning in neural networks, particularly focusing on system parameters such as firing rates and synaptic weights impact a network.
Difficulty level: Intermediate
Duration: 9:40
Speaker: : Dan Goodman

Course:
This lesson is a general overview of overarching concepts in neuroinformatics research, with a particular focus on clinical approaches to defining, measuring, studying, diagnosing, and treating various brain disorders. Also described are the complex, multi-level nature of brain disorders and the data associated with them, from genes and individual cells up to cortical microcircuits and whole-brain network dynamics. Given the heterogeneity of brain disorders and their underlying mechanisms, this lesson lays out a case for multiscale neuroscience data integration.
Difficulty level: Intermediate
Duration: 1:09:33
Speaker: : Sean Hill

This lesson explains the fundamental principles of neuronal communication, such as neuronal spiking, membrane potentials, and cellular excitability, and how these electrophysiological features of the brain may be modelled and simulated digitally.
Difficulty level: Intermediate
Duration: 1:20:42
Speaker: : Etay Hay