Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson is an overview of transcriptomics, from fundamental concepts of the central dogma and RNA sequencing at the single-cell level, to how genetic expression underlies diversity in cell phenotypes.
Difficulty level: Intermediate
Duration: 1:29:08
Speaker: : Shreejoy Tripathy

Course:
This lesson describes the principles underlying functional magnetic resonance imaging (fMRI), diffusion-weighted imaging (DWI), tractography, and parcellation. These tools and concepts are explained in a broader context of neural connectivity and mental health.
Difficulty level: Intermediate
Duration: 1:47:22
Speaker: : Erin Dickie and John Griffiths

This lesson breaks down the principles of Bayesian inference and how it relates to cognitive processes and functions like learning and perception. It is then explained how cognitive models can be built using Bayesian statistics in order to investigate how our brains interface with their environment.
This lesson corresponds to slides 1-64 in the PDF below.
Difficulty level: Intermediate
Duration: 1:28:14
Speaker: : Andreea Diaconescu

This lecture covers a lot of post-war developments in the science of the mind, focusing first on the cognitive revolution, and concluding with living machines.
Difficulty level: Beginner
Duration: 2:24:35
Speaker: : Paul F.M.J. Verschure

This lesson explores how researchers try to understand neural networks, particularly in the case of observing neural activity.
Difficulty level: Intermediate
Duration: 8:20
Speaker: : Marcus Ghosh
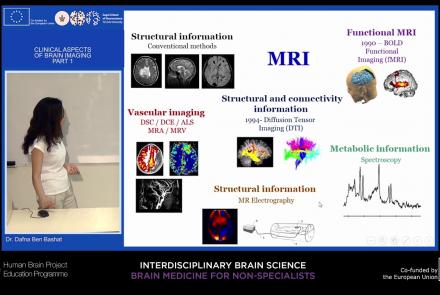
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

This lesson discusses both state-of-the-art detection and prevention schema in working with neurodegenerative diseases.
Difficulty level: Beginner
Duration: 1:02:29
Speaker: : Nir Giladi

This lecture provides an overview of depression (epidemiology and course of the disorder), clinical presentation, somatic co-morbidity, and treatment options.
Difficulty level: Beginner
Duration: 37:51
Speaker: : Barbara Sperner-Unterweger

This lecture gives an introduction to the types of glial cells, homeostasis (influence of cerebral blood flow and influence on neurons), insulation and protection of axons (myelin sheath; nodes of Ranvier), microglia and reactions of the CNS to injury.
Difficulty level: Beginner
Duration: 40:32
Speaker: : Christine Bandtlow
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier
Course:
This lesson discusses FAIR principles and methods currently in development for assessing FAIRness.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

In this lesson, you will hear about the current challenges regarding data management, as well as policies and resources aimed to address them.
Difficulty level: Beginner
Duration: 18:13
Speaker: : Mojib Javadi

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

This lecture provides an introduction to the Brain Imaging Data Structure (BIDS), a standard for organizing human neuroimaging datasets.
Difficulty level: Intermediate
Duration: 56:49
Speaker: : Chris Gorgolewski

Course:
This lecture presents an overview of functional brain parcellations, as well as a set of tutorials on bootstrap agregation of stable clusters (BASC) for fMRI brain parcellation.
Difficulty level: Advanced
Duration: 50:28
Speaker: : Pierre Bellec

Course:
This lecture covers the needs and challenges involved in creating a FAIR ecosystem for neuroimaging research.
Difficulty level: Beginner
Duration: 12:26
Speaker: : Camille Maumet

This lecture covers how to make modeling workflows FAIR by working through a practical example, dissecting the steps within the workflow, and detailing the tools and resources used at each step.
Difficulty level: Beginner
Duration: 15:14
Speaker: : Salvador Dura-Bernal

This lecture covers the NIDM data format within BIDS to make your datasets more searchable, and how to optimize your dataset searches.
Difficulty level: Beginner
Duration: 12:33
Speaker: : David Keator
This lecture covers the processes, benefits, and challenges involved in designing, collecting, and sharing FAIR neuroscience datasets.
Difficulty level: Beginner
Duration: 11:35
Speaker: : Julie Boyle & Valentina Borghesani