Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman

This lesson describes a definitional framework for fairness and health equity in the age of the algorithm. While acknowledging the impressive capability of machine learning to positively affect health equity, this talk outlines potential (and actual) pitfalls which come with such powerful tools, ultimately making the case for collaborative, interdisciplinary, and transparent science as a way to operationalize fairness in health equity.
Difficulty level: Beginner
Duration: 1:06:35
Speaker: : Laura Sikstrom

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This lesson is an overview of transcriptomics, from fundamental concepts of the central dogma and RNA sequencing at the single-cell level, to how genetic expression underlies diversity in cell phenotypes.
Difficulty level: Intermediate
Duration: 1:29:08
Speaker: : Shreejoy Tripathy

Course:
This lesson describes the principles underlying functional magnetic resonance imaging (fMRI), diffusion-weighted imaging (DWI), tractography, and parcellation. These tools and concepts are explained in a broader context of neural connectivity and mental health.
Difficulty level: Intermediate
Duration: 1:47:22
Speaker: : Erin Dickie and John Griffiths

This lecture discusses what defines an integrative approach regarding research and methods, including various study designs and models which are appropriate choices when attempting to bridge data domains; a necessity when whole-person modelling.
Difficulty level: Beginner
Duration: 1:28:14
Speaker: : Dan Felsky

This lesson explores how researchers try to understand neural networks, particularly in the case of observing neural activity.
Difficulty level: Intermediate
Duration: 8:20
Speaker: : Marcus Ghosh

As the previous lesson of this course described how researchers acquire neural data, this lesson will discuss how to go about interpreting and analysing the data.
Difficulty level: Intermediate
Duration: 9:24
Speaker: : Marcus Ghosh

In this lesson, you will learn about one particular aspect of decision making: reaction times. In other words, how long does it take to take a decision based on a stream of information arriving continuously over time?
Difficulty level: Intermediate
Duration: 6:01
Speaker: : Dan Goodman

In this lesson, you will learn in more detail about neuromorphic computing, that is, non-standard computational architectures that mimic some aspect of the way the brain works.
Difficulty level: Intermediate
Duration: 10:08
Speaker: : Dan Goodman

This video provides a very quick introduction to some of the neuromorphic sensing devices, and how they offer unique, low-power applications.
Difficulty level: Intermediate
Duration: 2:37
Speaker: : Dan Goodman
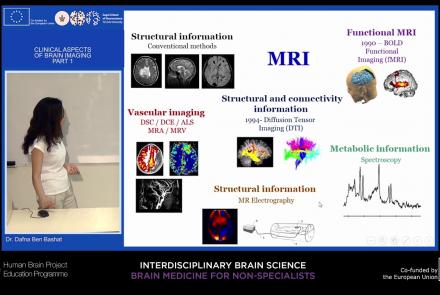
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

This lecture provides an overview of some of the essential concepts in neuropharmacology (e.g. receptor binding, agonism, antagonism), an introduction to pharmacodynamics and pharmacokinetics, and an overview of the drug discovery process relative to diseases of the central nervous system.
Difficulty level: Beginner
Duration: 45:47
Speaker: : Sandra Santos-Sierra
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier
Course:
This lesson discusses FAIR principles and methods currently in development for assessing FAIRness.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

This lecture provides an introduction to the Brain Imaging Data Structure (BIDS), a standard for organizing human neuroimaging datasets.
Difficulty level: Intermediate
Duration: 56:49
Speaker: : Chris Gorgolewski

Course:
This lecture presents an overview of functional brain parcellations, as well as a set of tutorials on bootstrap agregation of stable clusters (BASC) for fMRI brain parcellation.
Difficulty level: Advanced
Duration: 50:28
Speaker: : Pierre Bellec

Course:
This lecture covers the needs and challenges involved in creating a FAIR ecosystem for neuroimaging research.
Difficulty level: Beginner
Duration: 12:26
Speaker: : Camille Maumet
Course:
This lecture covers multiple aspects of FAIR neuroscience data: what makes it unique, the challenges to making it FAIR, the importance of overcoming these challenges, and how data governance comes into play.
Difficulty level: Beginner
Duration: 14:56
Speaker: : Damian Eke