Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This lesson is an overview of transcriptomics, from fundamental concepts of the central dogma and RNA sequencing at the single-cell level, to how genetic expression underlies diversity in cell phenotypes.
Difficulty level: Intermediate
Duration: 1:29:08
Speaker: : Shreejoy Tripathy

Course:
This lesson describes the principles underlying functional magnetic resonance imaging (fMRI), diffusion-weighted imaging (DWI), tractography, and parcellation. These tools and concepts are explained in a broader context of neural connectivity and mental health.
Difficulty level: Intermediate
Duration: 1:47:22
Speaker: : Erin Dickie and John Griffiths

This lecture covers a lot of post-war developments in the science of the mind, focusing first on the cognitive revolution, and concluding with living machines.
Difficulty level: Beginner
Duration: 2:24:35
Speaker: : Paul F.M.J. Verschure

This lesson delves into the the structure of one of the brain's most elemental computational units, the neuron, and how said structure influences computational neural network models.
Difficulty level: Intermediate
Duration: 6:33
Speaker: : Marcus Ghosh

In this lesson you will learn how machine learners and neuroscientists construct abstract computational models based on various neurophysiological signalling properties.
Difficulty level: Intermediate
Duration: 10:52
Speaker: : Dan Goodman

This lesson goes over the basic mechanisms of neural synapses, the space between neurons where signals may be transmitted.
Difficulty level: Intermediate
Duration: 7:03
Speaker: : Marcus Ghosh

While the previous lesson in the Neuro4ML course dealt with the mechanisms involved in individual synapses, this lesson discusses how synapses and their neurons' firing patterns may change over time.
Difficulty level: Intermediate
Duration: 4:48
Speaker: : Marcus Ghosh

Whereas the previous two lessons described the biophysical and signalling properties of individual neurons, this lesson describes properties of those units when part of larger networks.
Difficulty level: Intermediate
Duration: 6:00
Speaker: : Marcus Ghosh

This lesson describes spike timing-dependent plasticity (STDP), a biological process that adjusts the strength of connections between neurons in the brain, and how one can implement or mimic this process in a computational model. You will also find links for practical exercises at the bottom of this page.
Difficulty level: Intermediate
Duration: 12:50
Speaker: : Dan Goodman

In this lesson, you will learn about some of the many methods to train spiking neural networks (SNNs) with either no attempt to use gradients, or only use gradients in a limited or constrained way.
Difficulty level: Intermediate
Duration: 5:14
Speaker: : Dan Goodman

In this lesson, you will learn how to train spiking neural networks (SNNs) with a surrogate gradient method.
Difficulty level: Intermediate
Duration: 11:23
Speaker: : Dan Goodman

As the previous lesson of this course described how researchers acquire neural data, this lesson will discuss how to go about interpreting and analysing the data.
Difficulty level: Intermediate
Duration: 9:24
Speaker: : Marcus Ghosh

In this lesson, you will hear about some of the open issues in the field of neuroscience, as well as a discussion about whether neuroscience works, and how can we know?
Difficulty level: Intermediate
Duration: 6:54
Speaker: : Marcus Ghosh
Course:
This lesson gives an introduction to simple spiking neuron models.
Difficulty level: Beginner
Duration: 48 Slides
Speaker: : Zubin Bhuyan
This lesson provides an introduction to simple spiking neuron models.
Difficulty level: Beginner
Duration: 48 Slides
Speaker: : Zubin Bhuyan
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier
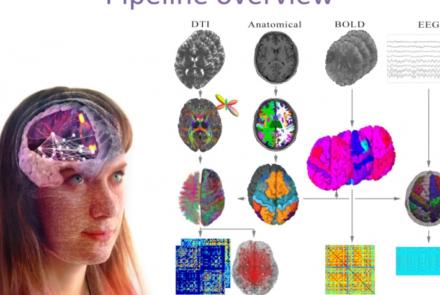
This presentation accompanies the paper entitled: An automated pipeline for constructing personalized virtual brains from multimodal neuroimaging data (see link below to download publication).
Difficulty level: Beginner
Duration: 4:56

This lecture provides an introduction to the Brain Imaging Data Structure (BIDS), a standard for organizing human neuroimaging datasets.
Difficulty level: Intermediate
Duration: 56:49
Speaker: : Chris Gorgolewski