Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This lesson is an overview of transcriptomics, from fundamental concepts of the central dogma and RNA sequencing at the single-cell level, to how genetic expression underlies diversity in cell phenotypes.
Difficulty level: Intermediate
Duration: 1:29:08
Speaker: : Shreejoy Tripathy

Course:
This lesson describes the principles underlying functional magnetic resonance imaging (fMRI), diffusion-weighted imaging (DWI), tractography, and parcellation. These tools and concepts are explained in a broader context of neural connectivity and mental health.
Difficulty level: Intermediate
Duration: 1:47:22
Speaker: : Erin Dickie and John Griffiths

This lesson delves into the the structure of one of the brain's most elemental computational units, the neuron, and how said structure influences computational neural network models.
Difficulty level: Intermediate
Duration: 6:33
Speaker: : Marcus Ghosh

This lesson goes over the basic mechanisms of neural synapses, the space between neurons where signals may be transmitted.
Difficulty level: Intermediate
Duration: 7:03
Speaker: : Marcus Ghosh

While the previous lesson in the Neuro4ML course dealt with the mechanisms involved in individual synapses, this lesson discusses how synapses and their neurons' firing patterns may change over time.
Difficulty level: Intermediate
Duration: 4:48
Speaker: : Marcus Ghosh

Whereas the previous two lessons described the biophysical and signalling properties of individual neurons, this lesson describes properties of those units when part of larger networks.
Difficulty level: Intermediate
Duration: 6:00
Speaker: : Marcus Ghosh

This lesson explores how researchers try to understand neural networks, particularly in the case of observing neural activity.
Difficulty level: Intermediate
Duration: 8:20
Speaker: : Marcus Ghosh

As the previous lesson of this course described how researchers acquire neural data, this lesson will discuss how to go about interpreting and analysing the data.
Difficulty level: Intermediate
Duration: 9:24
Speaker: : Marcus Ghosh
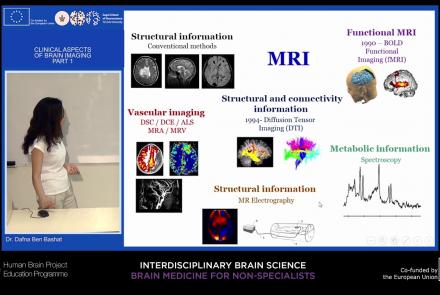
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

This lesson discusses both state-of-the-art detection and prevention schema in working with neurodegenerative diseases.
Difficulty level: Beginner
Duration: 1:02:29
Speaker: : Nir Giladi

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

This lecture provides an introduction to the Brain Imaging Data Structure (BIDS), a standard for organizing human neuroimaging datasets.
Difficulty level: Intermediate
Duration: 56:49
Speaker: : Chris Gorgolewski

Course:
This lecture presents an overview of functional brain parcellations, as well as a set of tutorials on bootstrap agregation of stable clusters (BASC) for fMRI brain parcellation.
Difficulty level: Advanced
Duration: 50:28
Speaker: : Pierre Bellec

Course:
This lecture covers FAIR atlases, including their background and construction, as well as how they can be created in line with the FAIR principles.
Difficulty level: Beginner
Duration: 14:24
Speaker: : Heidi Kleven
Course:
This lecture covers the needs and challenges involved in creating a FAIR ecosystem for neuroimaging research.
Difficulty level: Beginner
Duration: 12:26
Speaker: : Camille Maumet

This lecture covers the NIDM data format within BIDS to make your datasets more searchable, and how to optimize your dataset searches.
Difficulty level: Beginner
Duration: 12:33
Speaker: : David Keator
This lecture covers the processes, benefits, and challenges involved in designing, collecting, and sharing FAIR neuroscience datasets.
Difficulty level: Beginner
Duration: 11:35
Speaker: : Julie Boyle & Valentina Borghesani
This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz