Lesson type
Difficulty level

This is the first of two workshops on reproducibility in science, during which participants are introduced to concepts of FAIR and open science. After discussing the definition of and need for FAIR science, participants are walked through tutorials on installing and using Github and Docker, the powerful, open-source tools for versioning and publishing code and software, respectively.
Difficulty level: Intermediate
Duration: 1:20:58
Speaker: : Erin Dickie and Sejal Patel

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This lesson describes the fundamentals of genomics, from central dogma to design and implementation of GWAS, to the computation, analysis, and interpretation of polygenic risk scores.
Difficulty level: Intermediate
Duration: 1:28:16
Speaker: : Dan Felsky
This lesson contains the slides (pptx) of a lecture discussing the necessary concepts and tools for taking into account population stratification and admixture in the context of genome-wide association studies (GWAS). The free-access software Tractor and its advantages in GWAS are also discussed.
Difficulty level: Intermediate
Duration:
Speaker: : Dan Felsky

This lesson is an overview of transcriptomics, from fundamental concepts of the central dogma and RNA sequencing at the single-cell level, to how genetic expression underlies diversity in cell phenotypes.
Difficulty level: Intermediate
Duration: 1:29:08
Speaker: : Shreejoy Tripathy

Course:
This lesson describes the principles underlying functional magnetic resonance imaging (fMRI), diffusion-weighted imaging (DWI), tractography, and parcellation. These tools and concepts are explained in a broader context of neural connectivity and mental health.
Difficulty level: Intermediate
Duration: 1:47:22
Speaker: : Erin Dickie and John Griffiths

This lesson breaks down the principles of Bayesian inference and how it relates to cognitive processes and functions like learning and perception. It is then explained how cognitive models can be built using Bayesian statistics in order to investigate how our brains interface with their environment.
This lesson corresponds to slides 1-64 in the PDF below.
Difficulty level: Intermediate
Duration: 1:28:14
Speaker: : Andreea Diaconescu

This lecture covers a lot of post-war developments in the science of the mind, focusing first on the cognitive revolution, and concluding with living machines.
Difficulty level: Beginner
Duration: 2:24:35
Speaker: : Paul F.M.J. Verschure

This lesson explores how researchers try to understand neural networks, particularly in the case of observing neural activity.
Difficulty level: Intermediate
Duration: 8:20
Speaker: : Marcus Ghosh

In this lesson, you will learn in more detail about neuromorphic computing, that is, non-standard computational architectures that mimic some aspect of the way the brain works.
Difficulty level: Intermediate
Duration: 10:08
Speaker: : Dan Goodman

This video provides a very quick introduction to some of the neuromorphic sensing devices, and how they offer unique, low-power applications.
Difficulty level: Intermediate
Duration: 2:37
Speaker: : Dan Goodman
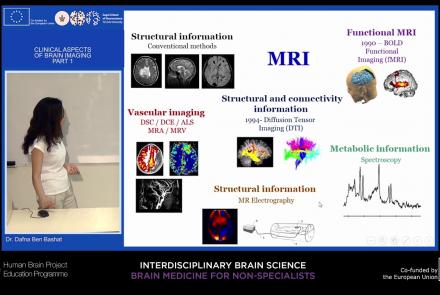
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

This lecture provides an overview of depression (epidemiology and course of the disorder), clinical presentation, somatic co-morbidity, and treatment options.
Difficulty level: Beginner
Duration: 37:51
Speaker: : Barbara Sperner-Unterweger

In this lesson, you will learn about how genetics can contribute to our understanding of psychiatric phenotypes.
Difficulty level: Beginner
Duration: 55:15
Speaker: : Sven Cichon

This lecture provides an overview of some of the essential concepts in neuropharmacology (e.g. receptor binding, agonism, antagonism), an introduction to pharmacodynamics and pharmacokinetics, and an overview of the drug discovery process relative to diseases of the central nervous system.
Difficulty level: Beginner
Duration: 45:47
Speaker: : Sandra Santos-Sierra
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

This lesson provides an introduction to the lifecycle of EEG/ERP data, describing the various phases through which these data pass, from collection to publication.
Difficulty level: Beginner
Duration: 35:30
Speaker: : Kateřina Vařeková

In this lesson you will learn about experimental design for EEG acquisition, as well as the first phases of the EEG/ERP data lifecycle.
Difficulty level: Beginner
Duration: 30:04
Speaker: : Kateřina Vařeková

This lesson provides an overview of the current regulatory measures in place regarding experimental data security and privacy.
Difficulty level: Beginner
Duration: 31:00
Speaker: : Kateřina Vařeková

In this lesson, you will learn the appropriate methods for collection of both data and associated metadata during EEG experiments.
Difficulty level: Beginner
Duration: 29:14
Speaker: : Kateřina Vařeková