Lesson type
Difficulty level

This video gives a brief introduction to Neuro4ML's lessons on neuromorphic computing - the use of specialized hardware which either directly mimics brain function or is inspired by some aspect of the way the brain computes.
Difficulty level: Intermediate
Duration: 3:56
Speaker: : Dan Goodman

In this lesson, you will learn in more detail about neuromorphic computing, that is, non-standard computational architectures that mimic some aspect of the way the brain works.
Difficulty level: Intermediate
Duration: 10:08
Speaker: : Dan Goodman

This video provides a very quick introduction to some of the neuromorphic sensing devices, and how they offer unique, low-power applications.
Difficulty level: Intermediate
Duration: 2:37
Speaker: : Dan Goodman

Course:
This lesson is a general overview of overarching concepts in neuroinformatics research, with a particular focus on clinical approaches to defining, measuring, studying, diagnosing, and treating various brain disorders. Also described are the complex, multi-level nature of brain disorders and the data associated with them, from genes and individual cells up to cortical microcircuits and whole-brain network dynamics. Given the heterogeneity of brain disorders and their underlying mechanisms, this lesson lays out a case for multiscale neuroscience data integration.
Difficulty level: Intermediate
Duration: 1:09:33
Speaker: : Sean Hill

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman

This is a continuation of the talk on the cellular mechanisms of neuronal communication, this time at the level of brain microcircuits and associated global signals like those measureable by electroencephalography (EEG). This lecture also discusses EEG biomarkers in mental health disorders, and how those cortical signatures may be simulated digitally.
Difficulty level: Intermediate
Duration: 1:11:04
Speaker: : Etay Hay
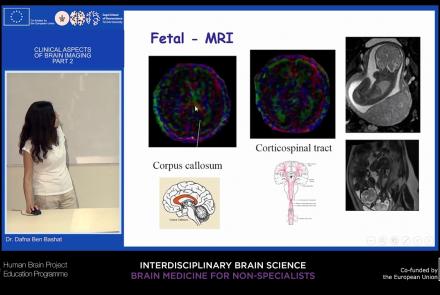
This lecture picks up from the previous lesson, providing an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 41:00
Speaker: : Dafna Ben Bashat

This lesson provides a basic introduction to clinical presentation of schizophrenia, its etiology, and current treatment options.
Difficulty level: Beginner
Duration: 51:49
Speaker: : Wolfgang Fleischhacker

This lecture focuses on the rationale for employing neuroimaging methods for movement disorders.
Difficulty level: Beginner
Duration: 1:04:04
Speaker: : Bogdan Draganski

This lecture provides an introduction to entropy in general, and multi-scale entropy (MSE) in particular, highlighting the potential clinical applications of the latter.
Difficulty level: Intermediate
Duration: 39:05
Speaker: : Jil Meier

This lecture provides an general introduction to epilepsy, as well as why and how TVB can prove useful in building and testing epileptic models.
Difficulty level: Intermediate
Duration: 37:12
Speaker: : Julie Courtiol

Course:
This lecture covers the rationale for developing the DAQCORD, a framework for the design, documentation, and reporting of data curation methods in order to advance the scientific rigour, reproducibility, and analysis of data.
Difficulty level: Intermediate
Duration: 17:08
Speaker: : Ari Ercole

In this session the Medical Informatics Platform (MIP) federated analytics is presented. The current and future analytical tools implemented in the MIP will be detailed along with the constructs, tools, processes, and restrictions that formulate the solution provided. MIP is a platform providing advanced federated analytics for diagnosis and research in clinical neuroscience research. It is targeting clinicians, clinical scientists and clinical data scientists. It is designed to help adopt advanced analytics, explore harmonized medical data of neuroimaging, neurophysiological and medical records as well as research cohort datasets, without transferring original clinical data. It can be perceived as a virtual database that seamlessly presents aggregated data from distributed sources, provides access and analyze imaging and clinical data, securely stored in hospitals, research archives and public databases. It leverages and re-uses decentralized patient data and research cohort datasets, without transferring original data. Integrated statistical analysis tools and machine learning algorithms are exposed over harmonized, federated medical data.
Difficulty level: Intermediate
Duration: 15:05
Speaker: : Giorgos Papanikos

The Medical Informatics Platform (MIP) is a platform providing federated analytics for diagnosis and research in clinical neuroscience research. The federated analytics is possible thanks to a distributed engine that executes computations and transfers information between the members of the federation (hospital nodes). In this talk the speaker will describe the process of designing and implementing new analytical tools, i.e. statistical and machine learning algorithms. Mr. Sakellariou will further describe the environment in which these federated algorithms run, the challenges and the available tools, the principles that guide its design and the followed general methodology for each new algorithm. One of the most important challenges which are faced is to design these tools in a way that does not compromise the privacy of the clinical data involved. The speaker will show how to address the main questions when designing such algorithms: how to decompose and distribute the computations and what kind of information to exchange between nodes, in order to comply with the privacy constraint mentioned above. Finally, also the subject of validating these federated algorithms will be briefly touched.
Difficulty level: Intermediate
Duration: 20:26
Speaker: : Jason Skellariou

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This is a hands-on tutorial on PLINK, the open source whole genome association analysis toolset. The aims of this tutorial are to teach users how to perform basic quality control on genetic datasets, as well as to identify and understand GWAS summary statistics.
Difficulty level: Intermediate
Duration: 1:27:18
Speaker: : Dan Felsky

This is a tutorial on using the open-source software PRSice to calculate a set of polygenic risk scores (PRS) for a study sample. Users will also learn how to read PRS into R, visualize distributions, and perform basic association analyses.
Difficulty level: Intermediate
Duration: 1:53:34
Speaker: : Dan Felsky

This lesson is an overview of transcriptomics, from fundamental concepts of the central dogma and RNA sequencing at the single-cell level, to how genetic expression underlies diversity in cell phenotypes.
Difficulty level: Intermediate
Duration: 1:29:08
Speaker: : Shreejoy Tripathy

This is a tutorial introducing participants to the basics of RNA-sequencing data and how to analyze its features using Seurat.
Difficulty level: Intermediate
Duration: 1:19:17
Speaker: : Sonny Chen