Lesson type
Difficulty level

This is a hands-on tutorial on PLINK, the open source whole genome association analysis toolset. The aims of this tutorial are to teach users how to perform basic quality control on genetic datasets, as well as to identify and understand GWAS summary statistics.
Difficulty level: Intermediate
Duration: 1:27:18
Speaker: : Dan Felsky

This is a tutorial on using the open-source software PRSice to calculate a set of polygenic risk scores (PRS) for a study sample. Users will also learn how to read PRS into R, visualize distributions, and perform basic association analyses.
Difficulty level: Intermediate
Duration: 1:53:34
Speaker: : Dan Felsky

Course:
This tutorial introduces pipelines and methods to compute brain connectomes from fMRI data. With corresponding code and repositories, participants can follow along and learn how to programmatically preprocess, curate, and analyze functional and structural brain data to produce connectivity matrices.
Difficulty level: Intermediate
Duration: 1:39:04
Speaker: : Erin Dickie and John Griffiths

This is a tutorial on designing a Bayesian inference model to map belief trajectories, with emphasis on gaining familiarity with Hierarchical Gaussian Filters (HGFs).
This lesson corresponds to slides 65-90 of the PDF below.
Difficulty level: Intermediate
Duration: 1:15:04
Speaker: : Daniel Hauke

This tutorial provides instruction on how to simulate brain tumors with TVB (reproducing publication: Marinazzo et al. 2020 Neuroimage). This tutorial comprises a didactic video, jupyter notebooks, and full data set for the construction of virtual brains from patients and health controls.
Difficulty level: Intermediate
Duration: 10:01

The tutorial on modelling strokes in TVB includes a didactic video and jupyter notebooks (reproducing publication: Falcon et al. 2016 eNeuro).
Difficulty level: Intermediate
Duration: 7:43

This tutorial covers the fundamentals of collaborating with Git and GitHub.
Difficulty level: Intermediate
Duration: 2:15:50
Speaker: : Elizabeth DuPre

Course:
This lesson provides an overview of Jupyter notebooks, Jupyter lab, and Binder, as well as their applications within the field of neuroimaging, particularly when it comes to the writing phase of your research.
Difficulty level: Intermediate
Duration: 50:28
Speaker: : Elizabeth DuPre
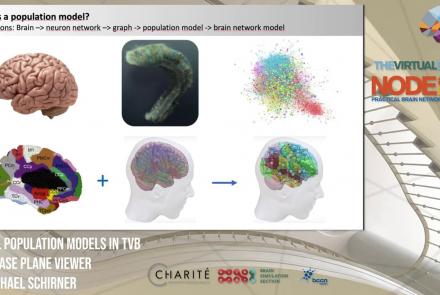
This lesson introduces population models and the phase plane, and is part of the The Virtual Brain (TVB) Node 10 Series, a 4-day workshop dedicated to learning about the full brain simulation platform TVB, as well as brain imaging, brain simulation, personalised brain models, and TVB use cases.
Difficulty level: Intermediate
Duration: 1:10:41
Speaker: : Michael Schirner

In this tutorial, you will learn how to run a typical TVB simulation.
Difficulty level: Intermediate
Duration: 1:29:13
Speaker: : Paul Triebkorn

This lesson introduces TVB-multi-scale extensions and other TVB tools which facilitate modeling and analyses of multi-scale data.
Difficulty level: Intermediate
Duration: 36:10
Speaker: : Dionysios Perdikis

This tutorial introduces The Virtual Mouse Brain (TVMB), walking users through the necessary steps for performing simulation operations on animal brain data.
Difficulty level: Intermediate
Duration: 42:43
Speaker: : Patrik Bey

In this tutorial, you will learn the necessary steps in modeling the brain of one of the most commonly studied animals among non-human primates, the macaque.
Difficulty level: Intermediate
Duration: 1:00:08
Speaker: : Julie Courtiol
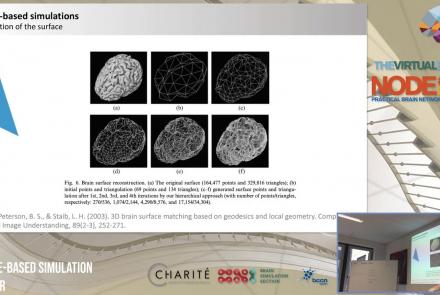
This lecture delves into cortical (i.e., surface-based) brain simulations, as well as subcortical (i.e., deep brain) stimulations, covering the definitions, motivations, and implementations of both.
Difficulty level: Intermediate
Duration: 39:05
Speaker: : Jil Meier

This lecture provides an introduction to entropy in general, and multi-scale entropy (MSE) in particular, highlighting the potential clinical applications of the latter.
Difficulty level: Intermediate
Duration: 39:05
Speaker: : Jil Meier

This lecture gives an overview of how to prepare and preprocess neuroimaging (EEG/MEG) data for use in TVB.
Difficulty level: Intermediate
Duration: 1:40:52
Speaker: : Paul Triebkorn

In this lecture, you will learn about various neuroinformatic resources which allow for 3D reconstruction of brain models.
Difficulty level: Intermediate
Duration: 1:36:57
Speaker: : Michael Schirner
Course:
This book was written with the goal of introducing researchers and students in a variety of research fields to the intersection of data science and neuroimaging. This book reflects our own experience of doing research at the intersection of data science and neuroimaging and it is based on our experience working with students and collaborators who come from a variety of backgrounds and have a variety of reasons for wanting to use data science approaches in their work. The tools and ideas that we chose to write about are all tools and ideas that we have used in some way in our own research. Many of them are tools that we use on a daily basis in our work. This was important to us for a few reasons: the first is that we want to teach people things that we ourselves find useful. Second, it allowed us to write the book with a focus on solving specific analysis tasks. For example, in many of the chapters you will see that we walk you through ideas while implementing them in code, and with data. We believe that this is a good way to learn about data analysis, because it provides a connecting thread from scientific questions through the data and its representation to implementing specific answers to these questions. Finally, we find these ideas compelling and fruitful. That’s why we were drawn to them in the first place. We hope that our enthusiasm about the ideas and tools described in this book will be infectious enough to convince the readers of their value.
Difficulty level: Intermediate
Duration:
Speaker: :

The Medical Informatics Platform (MIP) is a platform providing federated analytics for diagnosis and research in clinical neuroscience research. The federated analytics is possible thanks to a distributed engine that executes computations and transfers information between the members of the federation (hospital nodes). In this talk the speaker will describe the process of designing and implementing new analytical tools, i.e. statistical and machine learning algorithms. Mr. Sakellariou will further describe the environment in which these federated algorithms run, the challenges and the available tools, the principles that guide its design and the followed general methodology for each new algorithm. One of the most important challenges which are faced is to design these tools in a way that does not compromise the privacy of the clinical data involved. The speaker will show how to address the main questions when designing such algorithms: how to decompose and distribute the computations and what kind of information to exchange between nodes, in order to comply with the privacy constraint mentioned above. Finally, also the subject of validating these federated algorithms will be briefly touched.
Difficulty level: Intermediate
Duration: 20:26
Speaker: : Jason Skellariou