Lesson type
Difficulty level
In this lesson, users will get an overview of the EBRAINS integrated Fast TVB, a C implementation of TVB that is orders of magnitude faster than the original Python TVB, and capable of performing parallelizable simulations in the cloud.
Difficulty level: Intermediate
Duration: 8:38
Speaker: : Michael Schirner
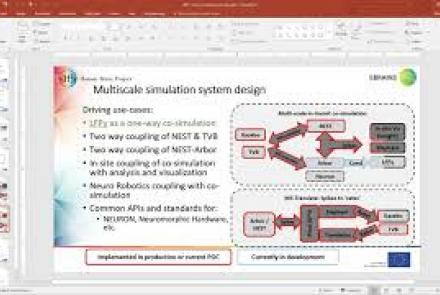
This lesson gives a brief overview of the multi-scale co-simulation between TVB-NEST and Elephant on the EBRAINS infrastructure.
Difficulty level: Intermediate
Duration: 6:05
Speaker: : Wouter Klijn
In this lesson, you will learn about the process of constructing models for TVB automatically on the EBRAINS infrastructure.
Difficulty level: Intermediate
Duration: 23:11
Speaker: : Michiel Van der Vlag and Sandra Diaz
Course:
The goal of computational modeling in behavioral and psychological science is using mathematical models to characterize behavioral (or neural) data. Over the past decade, this practice has revolutionized social psychological science (and neuroscience) by allowing researchers to formalize theories as constrained mathematical models and test specific hypotheses to explain unobservable aspects of complex social cognitive processes and behaviors. This course is composed of 4 modules in the format of Jupyter Notebooks. This course comprises lecture-based, discussion-based, and lab-based instruction. At least one-third of class sessions will be hands-on. We will discuss relevant book chapters and journal articles, and work with simulated and real data using the Python programming language (no prior programming experience necessary) as we survey some selected areas of research at the intersection of computational modeling and social behavior. These selected topics will span a broad set of social psychological abilities including (1) learning from and for others, (2) learning about others, and (3) social influence on decision-making and mental states. Rhoads, S. A. & Gan, L. (2022). Computational models of human social behavior and neuroscience - An open educational course and Jupyter Book to advance computational training. Journal of Open Source Education, 5(47), 146. https://doi.org/10.21105/jose.00146
Difficulty level: Intermediate
Duration:
Speaker: :
Course:
This book was written with the goal of introducing researchers and students in a variety of research fields to the intersection of data science and neuroimaging. This book reflects our own experience of doing research at the intersection of data science and neuroimaging and it is based on our experience working with students and collaborators who come from a variety of backgrounds and have a variety of reasons for wanting to use data science approaches in their work. The tools and ideas that we chose to write about are all tools and ideas that we have used in some way in our own research. Many of them are tools that we use on a daily basis in our work. This was important to us for a few reasons: the first is that we want to teach people things that we ourselves find useful. Second, it allowed us to write the book with a focus on solving specific analysis tasks. For example, in many of the chapters you will see that we walk you through ideas while implementing them in code, and with data. We believe that this is a good way to learn about data analysis, because it provides a connecting thread from scientific questions through the data and its representation to implementing specific answers to these questions. Finally, we find these ideas compelling and fruitful. That’s why we were drawn to them in the first place. We hope that our enthusiasm about the ideas and tools described in this book will be infectious enough to convince the readers of their value.
Difficulty level: Intermediate
Duration:
Speaker: :

The Medical Informatics Platform (MIP) is a platform providing federated analytics for diagnosis and research in clinical neuroscience research. The federated analytics is possible thanks to a distributed engine that executes computations and transfers information between the members of the federation (hospital nodes). In this talk the speaker will describe the process of designing and implementing new analytical tools, i.e. statistical and machine learning algorithms. Mr. Sakellariou will further describe the environment in which these federated algorithms run, the challenges and the available tools, the principles that guide its design and the followed general methodology for each new algorithm. One of the most important challenges which are faced is to design these tools in a way that does not compromise the privacy of the clinical data involved. The speaker will show how to address the main questions when designing such algorithms: how to decompose and distribute the computations and what kind of information to exchange between nodes, in order to comply with the privacy constraint mentioned above. Finally, also the subject of validating these federated algorithms will be briefly touched.
Difficulty level: Intermediate
Duration: 20:26
Speaker: : Jason Skellariou